Setup Prerequisites
Goals
In this section we will setup a single node Kubernetes cluster.
You can skip this section if you have an existing Kubernetes cluster with a dynamic volume provisioner.
Overview
Kubernetes (K8s) is an open-source system for automating deployment, scaling, and management of containerized applications. For this tutorial we will setup a single node Kubernetes cluster using Vagrant and VirtualBox.
Prerequisites
- Vagrant 2.2.5 or later
- VirtualBox 6.0.14 or later
- Laptop or server with at least 4 CPU cores and 16 Gig of RAM
Install Vagrant
Follow the instructions here to install Vagrant for your operating system.
Install Virtual Box
Follow the instructions here to install VirtualBox for your operating system.
Download Virtualbox Image
Clone the repository for this workshop.
git clone https://github.com/tfworldkatib/tutorial
cd tutorial
Start the Vagrant virtual machine that we will use
vagrant up
Sample Output
vagrant up Bringing machine 'default' up with 'virtualbox' provider... ==> default: Importing base box 'minikatib/tfworld'... ==> default: Matching MAC address for NAT networking... ==> default: Checking if box 'minikatib/tfworld' version '0.2.0' is up to date... ==> default: Setting the name of the VM: tfworld_default_1571554286050_26802 ==> default: Fixed port collision for 22 => 2222. Now on port 2200. ==> default: Clearing any previously set network interfaces... ==> default: Preparing network interfaces based on configuration... default: Adapter 1: nat ==> default: Forwarding ports... default: 31230 (guest) => 31230 (host) (adapter 1) default: 22 (guest) => 2200 (host) (adapter 1) ==> default: Running 'pre-boot' VM customizations... ==> default: Booting VM... ==> default: Waiting for machine to boot. This may take a few minutes... default: SSH address: 127.0.0.1:2200 default: SSH username: vagrant default: SSH auth method: private key ==> default: Machine booted and ready! ==> default: Checking for guest additions in VM... ==> default: Mounting shared folders... default: /vagrant => /Users/neelimam/minikatib/t3/tfworld ==> default: Running provisioner: shell... default: Running: inline script default: [init] Using Kubernetes version: v1.14.8 default: [preflight] Running pre-flight checks default: [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' default: [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ default: [preflight] Pulling images required for setting up a Kubernetes cluster default: [preflight] This might take a minute or two, depending on the speed of your internet connection default: [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' default: [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" default: [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" default: [kubelet-start] Activating the kubelet service default: [certs] Using certificateDir folder "/etc/kubernetes/pki" default: [certs] Generating "ca" certificate and key default: [certs] Generating "apiserver" certificate and key default: [certs] apiserver serving cert is signed for DNS names [katib kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.0.2.15] default: [certs] Generating "apiserver-kubelet-client" certificate and key default: [certs] Generating "front-proxy-ca" certificate and key default: [certs] Generating "front-proxy-client" certificate and key default: [certs] Generating "etcd/ca" certificate and key default: [certs] Generating "etcd/server" certificate and key default: [certs] etcd/server serving cert is signed for DNS names [katib localhost] and IPs [10.0.2.15 127.0.0.1 ::1] default: [certs] Generating "etcd/peer" certificate and key default: [certs] etcd/peer serving cert is signed for DNS names [katib localhost] and IPs [10.0.2.15 127.0.0.1 ::1] default: [certs] Generating "etcd/healthcheck-client" certificate and key default: [certs] Generating "apiserver-etcd-client" certificate and key default: [certs] Generating "sa" key and public key default: [kubeconfig] Using kubeconfig folder "/etc/kubernetes" default: [kubeconfig] Writing "admin.conf" kubeconfig file default: [kubeconfig] Writing "kubelet.conf" kubeconfig file default: [kubeconfig] Writing "controller-manager.conf" kubeconfig file default: [kubeconfig] Writing "scheduler.conf" kubeconfig file default: [control-plane] Using manifest folder "/etc/kubernetes/manifests" default: [control-plane] Creating static Pod manifest for "kube-apiserver" default: [control-plane] Creating static Pod manifest for "kube-controller-manager" default: [control-plane] Creating static Pod manifest for "kube-scheduler" default: [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" default: [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s default: [apiclient] All control plane components are healthy after 36.003972 seconds default: [upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace default: [kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster default: [upload-certs] Skipping phase. Please see --experimental-upload-certs default: [mark-control-plane] Marking the node katib as control-plane by adding the label "node-role.kubernetes.io/master=''" default: [mark-control-plane] Marking the node katib as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] default: [bootstrap-token] Using token: 6cvjk2.7kwbwb0oedxmmxnf default: [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles default: [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials default: [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token default: [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster default: [bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace default: [addons] Applied essential addon: CoreDNS default: [addons] Applied essential addon: kube-proxy default: default: Your Kubernetes control-plane has initialized successfully! default: default: To start using your cluster, you need to run the following as a regular user: default: default: mkdir -p $HOME/.kube default: sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config default: sudo chown $(id -u):$(id -g) $HOME/.kube/config default: default: You should now deploy a pod network to the cluster. default: Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: default: https://kubernetes.io/docs/concepts/cluster-administration/addons/ default: default: Then you can join any number of worker nodes by running the following on each as root: default: default: kubeadm join 10.0.2.15:6443 --token 6cvjk2.7kwbwb0oedxmmxnf \ default: --discovery-token-ca-cert-hash sha256:081c1fe5d9e42a8d2c85ffc7465a3b606d8ae90e7511861cb7eeba3397a7e3f5 default: node/katib untainted default: configmap/kube-router-cfg created default: daemonset.apps/kube-router created default: serviceaccount/kube-router created default: clusterrole.rbac.authorization.k8s.io/kube-router created default: clusterrolebinding.rbac.authorization.k8s.io/kube-router created default: persistentvolume/data-kf-nfs-server-provisioner-0 createdvagrant up downloads the Virtual Box image for this tutorial and powers it on.
This may take 15-20 minutes and at the end of it you will have a single node Kubernetes cluster.
Setup Kubernetes
Goals
In this section we will configure the single node Kubernetes cluster to support persistent storage.
You can skip this section if you have an existing Kubernetes cluster with a dynamic volume provisioner.
Troubleshooting:
If you see an SSL error during vagrant up, please add the following to Vagrantfile after line 11.
config.vm.box_download_insecure = true
If you have an existing image that you were trying to download, you need to delete it. Go to the tutorial folder and do the following:
vagrant destroy
Add Virtual Box image using the USB box file.
vagrant box add --provider=virtualbox minikatib/tfworld package.box
Install Kubernetes
Login to the VM
vagrant ssh
Sample Output
Welcome to Ubuntu 18.04.2 LTS (GNU/Linux 4.15.0-51-generic x86_64)- Documentation: https://help.ubuntu.com
- Management: https://landscape.canonical.com
- Support: https://ubuntu.com/advantage
System information as of Sun Oct 20 06:53:33 UTC 2019
System load: 0.87 Users logged in: 0 Usage of /: 18.6% of 61.80GB IP address for eth0: 10.0.2.15 Memory usage: 14% IP address for docker0: 172.17.0.1 Swap usage: 0% IP address for kube-bridge: 192.168.0.1 Processes: 160
-
Kata Containers are now fully integrated in Charmed Kubernetes 1.16! Yes, charms take the Krazy out of K8s Kata Kluster Konstruction.
https://ubuntu.com/kubernetes/docs/release-notes
111 packages can be updated. 60 updates are security updates.
Last login: Sun Oct 20 03:54:17 2019 from 10.0.2.2
Kubernetes has been started during VM provisioning. You can confirm this as follows.
kubectl get nodes
Sample Output
NAME STATUS ROLES AGE VERSION katib Ready master 2m15s v1.14.8Start helm and install NFS helm chart. This provides dynamic provisioning for Kubernetes workloads.
cd $HOME/tfworld/setup/k8s-config/
./start-helm.sh
This will take a couple of minutes.
Sample Output
serviceaccount/tiller created clusterrolebinding.rbac.authorization.k8s.io/tiller created Creating /home/vagrant/.helm Creating /home/vagrant/.helm/repository Creating /home/vagrant/.helm/repository/cache Creating /home/vagrant/.helm/repository/local Creating /home/vagrant/.helm/plugins Creating /home/vagrant/.helm/starters Creating /home/vagrant/.helm/cache/archive Creating /home/vagrant/.helm/repository/repositories.yaml Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com Adding local repo with URL: http://127.0.0.1:8879/charts $HELM_HOME has been configured at /home/vagrant/.helm.Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
To prevent this, run helm init with the --tiller-tls-verify flag.
For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation
Hang tight while we grab the latest from your chart repositories...
...Skip local chart repository
...Successfully got an update from the "stable" chart repository
Update Complete.
NAME: kf
LAST DEPLOYED: Sun Oct 20 06:56:39 2019
NAMESPACE: kube-system
STATUS: DEPLOYED
RESOURCES: ==> v1/ClusterRole NAME AGE kf-nfs-server-provisioner 1s
==> v1/ClusterRoleBinding NAME AGE kf-nfs-server-provisioner 1s
==> v1/Pod(related) NAME READY STATUS RESTARTS AGE kf-nfs-server-provisioner-0 0/1 Pending 0 1s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kf-nfs-server-provisioner ClusterIP 10.100.45.158
==> v1/ServiceAccount NAME SECRETS AGE kf-nfs-server-provisioner 1 1s
==> v1/StorageClass NAME PROVISIONER AGE nfs cluster.local/kf-nfs-server-provisioner 1s
==> v1beta2/StatefulSet NAME READY AGE kf-nfs-server-provisioner 0/1 1s
NOTES: The NFS Provisioner service has now been installed.
A storage class named 'nfs' has now been created and is available to provision dynamic volumes.
You can use this storageclass by creating a PersistentVolumeClaim with the
correct storageClassName attribute. For example:
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-dynamic-volume-claim
spec:
storageClassName: "nfs"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
Congratulations! Now you have a single node Kubernetes cluster on your laptop. The magic of Kubernetes allows you to run your workloads on this tiny Kubernetes cluster identical to how you would on your production cluster in your datacenter or in a cloud.
Kubernetes Architecture
A Kubernetes cluster consists of some master components and some worker components. In a single node Kubernetes cluster, master and worker components may run on the same node. In a production Kubernetes cluster you typically have one or more master nodes and many worker nodes.
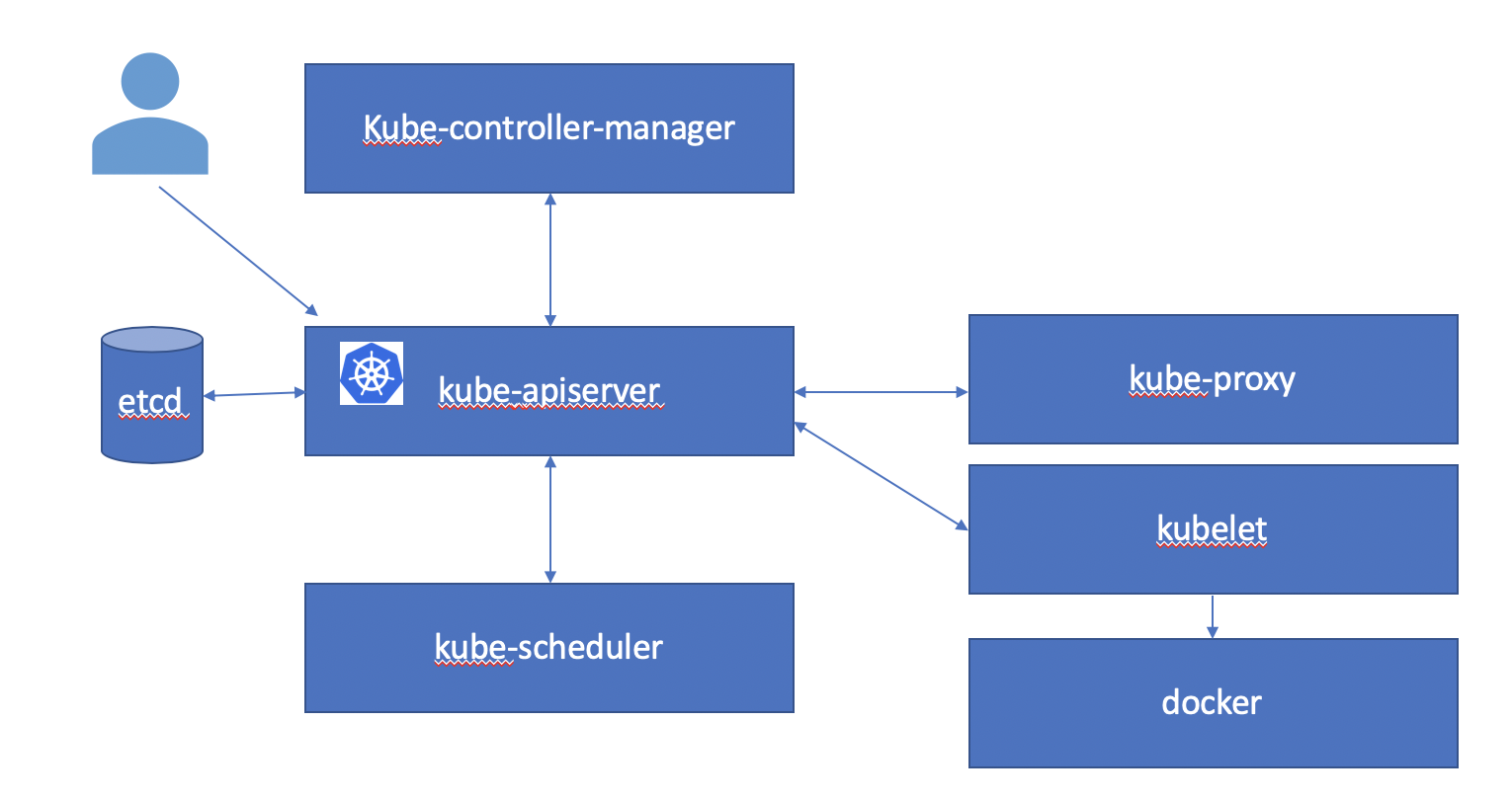
Kubernetes API server is the primary interface to an end user - either using kubectl or client-go or an application using the Kubernetes API.
Kubernetes API server manages versioned resources. You can add new resource types to a Kubernetes API server.
Pods, Deployments, Services are examples on built in resources or Kinds. In this tutorial we will be working with custom resources like Experiments, Suggestions and Trials. Resources are grouped together into API groups and are versioned.
You can explore the API groups and resources available on your Kubernetes cluster as follows.
kubectl api-versions
Sample Output
admissionregistration.k8s.io/v1beta1 apiextensions.k8s.io/v1beta1 apiregistration.k8s.io/v1 apiregistration.k8s.io/v1beta1 apps/v1 apps/v1beta1 apps/v1beta2 authentication.k8s.io/v1 authentication.k8s.io/v1beta1 authorization.k8s.io/v1 authorization.k8s.io/v1beta1 autoscaling/v1 autoscaling/v2beta1 autoscaling/v2beta2 batch/v1 batch/v1beta1 certificates.k8s.io/v1beta1 coordination.k8s.io/v1 coordination.k8s.io/v1beta1 events.k8s.io/v1beta1 extensions/v1beta1 kubeflow.org/v1 kubeflow.org/v1alpha3 networking.k8s.io/v1 networking.k8s.io/v1beta1 node.k8s.io/v1beta1 policy/v1beta1 rbac.authorization.k8s.io/v1 rbac.authorization.k8s.io/v1beta1 scheduling.k8s.io/v1 scheduling.k8s.io/v1beta1 storage.k8s.io/v1 storage.k8s.io/v1beta1 v1You can see the available Kubernetes resources(Kinds) as follows.
kubectl api-resources
Sample Output
NAME SHORTNAMES APIGROUP NAMESPACED KIND bindings true Binding componentstatuses cs false ComponentStatus configmaps cm true ConfigMap endpoints ep true Endpoints events ev true Event limitranges limits true LimitRange namespaces ns false Namespace nodes no false Node persistentvolumeclaims pvc true PersistentVolumeClaim persistentvolumes pv false PersistentVolume pods po true Pod podtemplates true PodTemplate replicationcontrollers rc true ReplicationController resourcequotas quota true ResourceQuota secrets true Secret serviceaccounts sa true ServiceAccount services svc true Service mutatingwebhookconfigurations admissionregistration.k8s.io false MutatingWebhookConfiguration validatingwebhookconfigurations admissionregistration.k8s.io false ValidatingWebhookConfiguration customresourcedefinitions crd,crds apiextensions.k8s.io false CustomResourceDefinition apiservices apiregistration.k8s.io false APIService controllerrevisions apps true ControllerRevision daemonsets ds apps true DaemonSet deployments deploy apps true Deployment replicasets rs apps true ReplicaSet statefulsets sts apps true StatefulSet tokenreviews authentication.k8s.io false TokenReview localsubjectaccessreviews authorization.k8s.io true LocalSubjectAccessReview selfsubjectaccessreviews authorization.k8s.io false SelfSubjectAccessReview selfsubjectrulesreviews authorization.k8s.io false SelfSubjectRulesReview subjectaccessreviews authorization.k8s.io false SubjectAccessReview horizontalpodautoscalers hpa autoscaling true HorizontalPodAutoscaler cronjobs cj batch true CronJob jobs batch true Job certificatesigningrequests csr certificates.k8s.io false CertificateSigningRequest leases coordination.k8s.io true Lease events ev events.k8s.io true Event daemonsets ds extensions true DaemonSet deployments deploy extensions true Deployment ingresses ing extensions true Ingress networkpolicies netpol extensions true NetworkPolicy podsecuritypolicies psp extensions false PodSecurityPolicy replicasets rs extensions true ReplicaSet experiments kubeflow.org true Experiment pytorchjobs kubeflow.org true PyTorchJob suggestions kubeflow.org true Suggestion tfjobs kubeflow.org true TFJob trials kubeflow.org true Trial ingresses ing networking.k8s.io true Ingress networkpolicies netpol networking.k8s.io true NetworkPolicy runtimeclasses node.k8s.io false RuntimeClass poddisruptionbudgets pdb policy true PodDisruptionBudget podsecuritypolicies psp policy false PodSecurityPolicy clusterrolebindings rbac.authorization.k8s.io false ClusterRoleBinding clusterroles rbac.authorization.k8s.io false ClusterRole rolebindings rbac.authorization.k8s.io true RoleBinding roles rbac.authorization.k8s.io true Role priorityclasses pc scheduling.k8s.io false PriorityClass csidrivers storage.k8s.io false CSIDriver csinodes storage.k8s.io false CSINode storageclasses sc storage.k8s.io false StorageClass volumeattachments storage.k8s.io false VolumeAttachmentPod
Specification for a Kubernetes resource can be done via yaml file. Kubernetes manages pods instead of containers. A pod can contain one or more containers. Containers in a pod share resources and common local network. As we will see during Katib section of the tutorial, Katib injects a metrics container to the model training pod. Here is a yaml file to run mnist example as a pod. The max_steps is set to 1 to speed-up running the mnist example.
Mnist pod example
apiVersion: v1
kind: Pod
metadata:
name: mnistpod
spec:
containers:
- name: mnist
image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
command:
- "python"
- "/var/tf_mnist/mnist_with_summaries.py"
- "--max_steps=1"
- "--batch_size=2"
restartPolicy: Never
cd $HOME
git clone https://github.com/tfworldkatib/tutorial.git
cd $HOME/tutorial/examples
kubectl apply -f mnistpod.yaml
Sample Output
pod/mnistpod createdCheck that the Pod mnistpod has started.
kubectl get pods
Sample Output
NAME STATUS AGE mnistpod Running 2sCheck the logs of the Pod mnistpod
kubectl logs -f mnistpod
Sample Output
WARNING:tensorflow:From /var/tf_mnist/mnist_with_summaries.py:39: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version. Instructions for updating: Please write your own downloading logic. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:252: wrapped_fn (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version. Instructions for updating: Please use urllib or similar directly. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: __init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models. 2019-10-29 01:42:17.348035: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Extracting /tmp/tensorflow/mnist/input_data/train-images-idx3-ubyte.gz Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Extracting /tmp/tensorflow/mnist/input_data/train-labels-idx1-ubyte.gz Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Extracting /tmp/tensorflow/mnist/input_data/t10k-images-idx3-ubyte.gz Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. Extracting /tmp/tensorflow/mnist/input_data/t10k-labels-idx1-ubyte.gz Accuracy at step 0: 0.1005Notice the Accuracy output from the mnistpod. This will be used by Katib to find accuracy results from a given hyperparameter set.
Delete the Pod mnistpod
kubectl delete -f mnistpod.yaml
CRD (Custom Resource Definition)
Kubernetes supports various types of extension capabilities at all layers, starting with the API server, scheduler, controllers all the way to the kubelet. One of the common patterns used to add new resources and capabilities to the Kubernetes API server is called the Operator Pattern. This consists of creating a custom resource(Kind) and a controller that manages this custom resource.
Kubeflow and Katib use this extensively. This allows Kubeflow and Katib to be integrated with Kubernetes. You can manage and interact with Kubeflow and Katib components just as you interact with any other Kubernetes component!
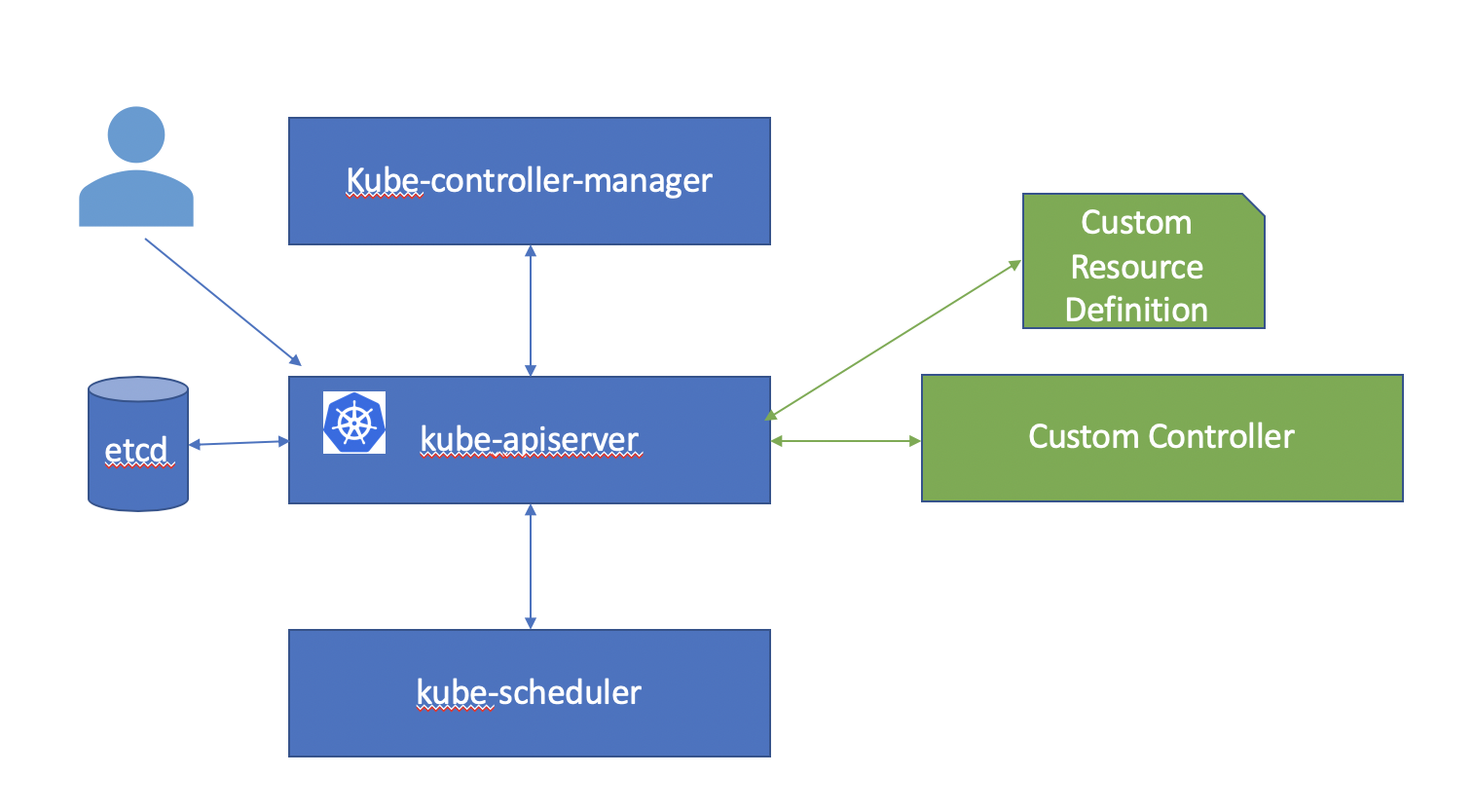
You can see the available Kubernetes custom resource definitions as follows.
kubectl get crds
Sample Output
NAME CREATED AT experiments.kubeflow.org 2019-10-26T21:00:25Z pytorchjobs.kubeflow.org 2019-10-26T21:00:27Z suggestions.kubeflow.org 2019-10-26T21:00:25Z tfjobs.kubeflow.org 2019-10-26T21:00:27Z trials.kubeflow.org 2019-10-26T21:00:25ZKatib
Katib is a scalable and extensible Automatic Machine Learning(AutoML) framework on Kubernetes. It supports Hyperparameter tuning and neural architecture search. It enables users to discover models that are as good as hand-crafted models, without having to go through the laborious process of manual configuration and iteration.
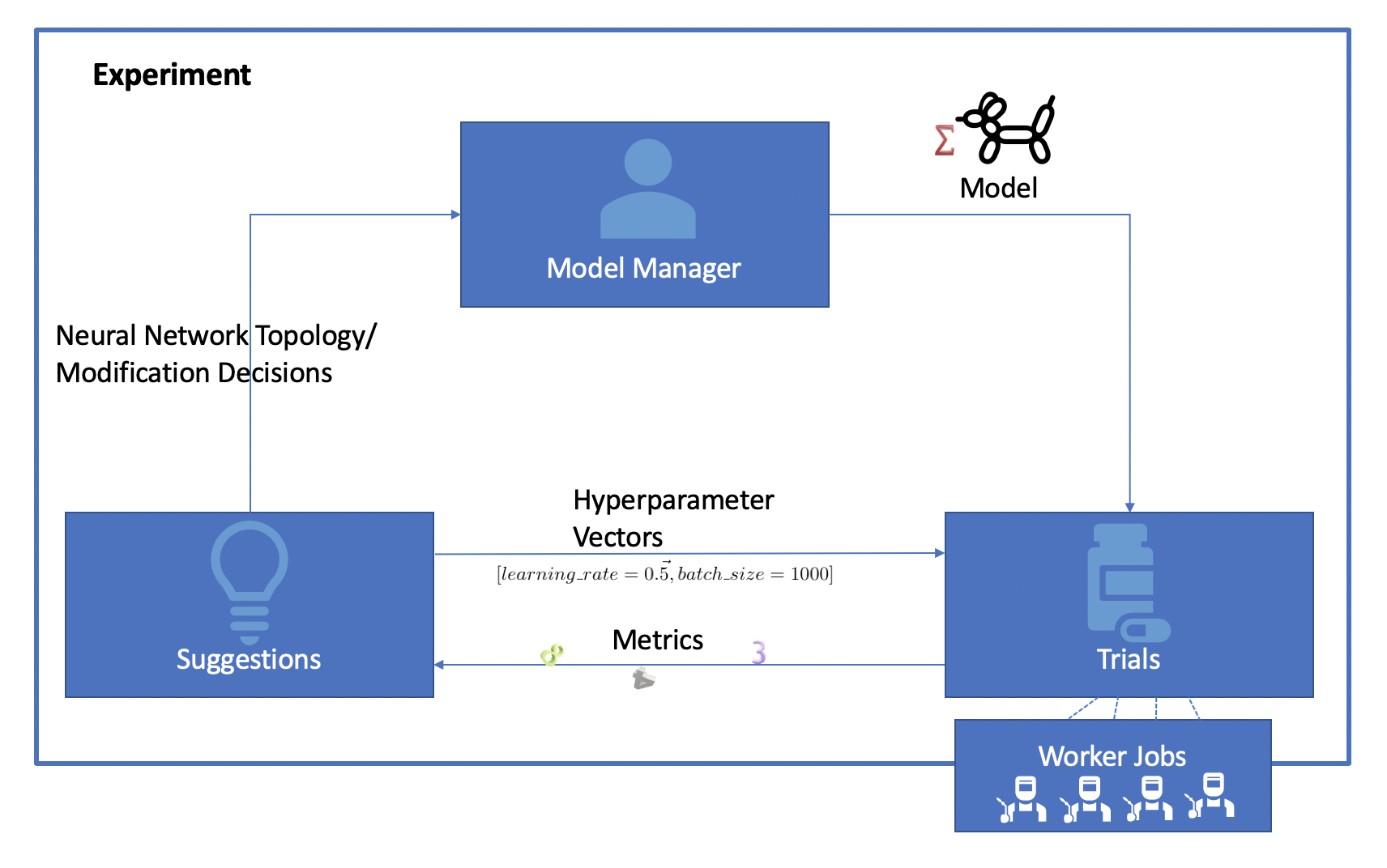
Katib organizes an optimization or neural architecture search as an Experiment.
AutoML algorithms run in an interactive manner. An Experiment defines the search space, metrics target and maximum number of iterations. Katib searches iteratively in the search space to meet the metrics target or for the maximum number of iterations.
Katib supports two different mechanisms for AutoML - Hyperparameter Tuning and Neural Architecture Search.
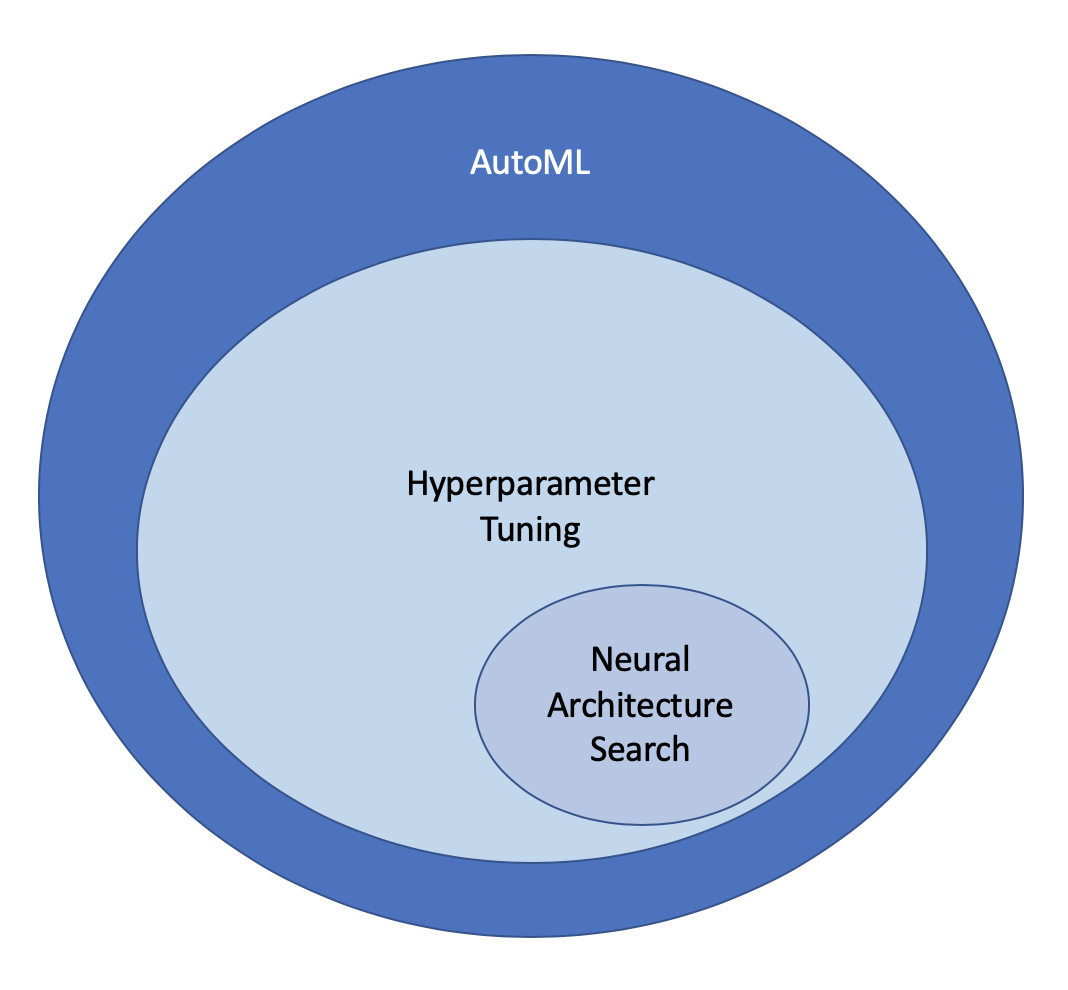
Etymology
Katib stands for secretary in Arabic. As Vizier stands for a high official or a prime minister in Arabic, this project Katib is named in the honor of Vizier.
Hyperparameter Tuning
Hyperparameter tuning finds the optimal hyperparameter vector for a given model architecture. In each iteration Katib uses a Suggestion algorithm to generate a candidate hyperparameter vector. The candidate hyperparameters are given to a Trial that provides training and validation services. The metrics collected from that trial are fed into the Suggestion algorithm to generate the candidate vector for the next iteration. This process continues till we reach the desired metric goal or the maximum number of iterations if complete.

In this tutorial we will focus on Hyperparameter tuning.
Neural Architecture Search
Neural Architecture Search finds the optimal neural architecture for a given data set.
Installation
Let us start with the install of Katib.
cd $HOME
git clone https://github.com/tfworldkatib/tutorial.git
cd $HOME/tutorial/setup/katib-install
./deploy.sh
Sample Output
``` + kubectl apply -f v1alpha3 namespace/kubeflow created + kubectl apply -f v1alpha3/katib-controller customresourcedefinition.apiextensions.k8s.io/experiments.kubeflow.org created customresourcedefinition.apiextensions.k8s.io/suggestions.kubeflow.org created customresourcedefinition.apiextensions.k8s.io/trials.kubeflow.org created configmap/katib-config created deployment.apps/katib-controller created clusterrole.rbac.authorization.k8s.io/katib-controller created serviceaccount/katib-controller created clusterrolebinding.rbac.authorization.k8s.io/katib-controller created secret/katib-controller created service/katib-controller created configmap/trial-template created + kubectl apply -f v1alpha3/manager deployment.extensions/katib-manager created service/katib-manager created + kubectl apply -f v1alpha3/pv persistentvolume/katib-mysql created persistentvolumeclaim/katib-mysql created + kubectl apply -f v1alpha3/db deployment.extensions/katib-db created secret/katib-db-secrets created service/katib-db created + kubectl apply -f v1alpha3/ui deployment.extensions/katib-ui created clusterrole.rbac.authorization.k8s.io/katib-ui created serviceaccount/katib-ui created clusterrolebinding.rbac.authorization.k8s.io/katib-ui created service/katib-ui created + kubectl apply -f tf-job customresourcedefinition.apiextensions.k8s.io/tfjobs.kubeflow.org created serviceaccount/tf-job-dashboard created serviceaccount/tf-job-operator created clusterrole.rbac.authorization.k8s.io/kubeflow-tfjobs-admin created clusterrole.rbac.authorization.k8s.io/kubeflow-tfjobs-edit created clusterrole.rbac.authorization.k8s.io/kubeflow-tfjobs-view created clusterrole.rbac.authorization.k8s.io/tf-job-operator created clusterrolebinding.rbac.authorization.k8s.io/tf-job-operator created service/tf-job-operator created deployment.apps/tf-job-operator created + kubectl apply -f pytorch customresourcedefinition.apiextensions.k8s.io/pytorchjobs.kubeflow.org created serviceaccount/pytorch-operator created clusterrole.rbac.authorization.k8s.io/kubeflow-pytorchjobs-admin created clusterrole.rbac.authorization.k8s.io/kubeflow-pytorchjobs-edit created clusterrole.rbac.authorization.k8s.io/kubeflow-pytorchjobs-view created clusterrole.rbac.authorization.k8s.io/pytorch-operator created clusterrolebinding.rbac.authorization.k8s.io/pytorch-operator created service/pytorch-operator created deployment.apps/pytorch-operator created ```Check that the Katib core components are installed and ready.
kubectl -n kubeflow get pods
Sample Output
NAME READY STATUS RESTARTS AGE
katib-controller-7665868558-nfghw 1/1 Running 1 80s
katib-db-594756f779-dxttq 1/1 Running 0 81s
katib-manager-769b7bcbfb-7vvgx 1/1 Running 0 81s
katib-ui-854969c97-tl4wg 1/1 Running 0 79s
pytorch-operator-794899d49b-ww59g 1/1 Running 0 79s
tf-job-operator-7b589f5f5f-fpr2p 1/1 Running 0 80s
katib-controller, katib-manager, katib-db and katib-ui are the core components of Katib.
We have also installed a tf-job-operator and pytorch-operator to be able to run TensorFlow Jobs and PyTorch Jobs.
You can access Katib UI here. If you are running on a non-Vagrant Kubernetes Cluster, you may need to use the Node IP for your VM or change the katib-ui service to use a LoadBalancer.
Hyperparameter Tuning
This step takes about 10-15 mins to complete. Your Vagrant VM will likely be very busy at this time. Please do not try to run multiple experiments on this simultaneously.
Katib has an extensible architecture for Suggestion algorithms. Today we will look at some of the in-built models.
Let us start with the random algorithm using a TensorFlow Job example.
Random Search
Random search is a black box algorithm for searching for an optimal hyperparameter vector. It assumes nothing about the model and trials can be run in parallel.
Random search selects points at random from the entire search space.
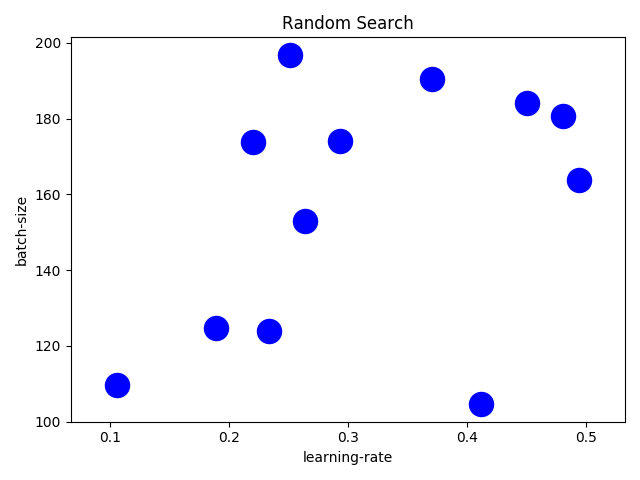
Random search provides a good coverage for multiple hyperparameters in the search space. If you want a generic baseline, it is always a good idea to start with a Random search.
Now let us create a random search experiment using Katib.
Experiment
Let us start by creating an experiment.
Random search experiment
apiVersion: "kubeflow.org/v1alpha3"
kind: Experiment
metadata:
namespace: kubeflow
name: tfjob-random
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy_1
algorithm:
algorithmName: random
metricsCollectorSpec:
source:
fileSystemPath:
path: /train
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: --learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
- name: --batch_size
parameterType: int
feasibleSpace:
min: "100"
max: "200"
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: "kubeflow.org/v1"
kind: TFJob
metadata:
name: {{.Trial}}
namespace: {{.NameSpace}}
spec:
tfReplicaSpecs:
Worker:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
imagePullPolicy: IfNotPresent
command:
- "python"
- "/var/tf_mnist/mnist_with_summaries.py"
- "--log_dir=/train/metrics"
{{- with .HyperParameters}}
{{- range .}}
- "{{.Name}}={{.Value}}"
{{- end}}
{{- end}}
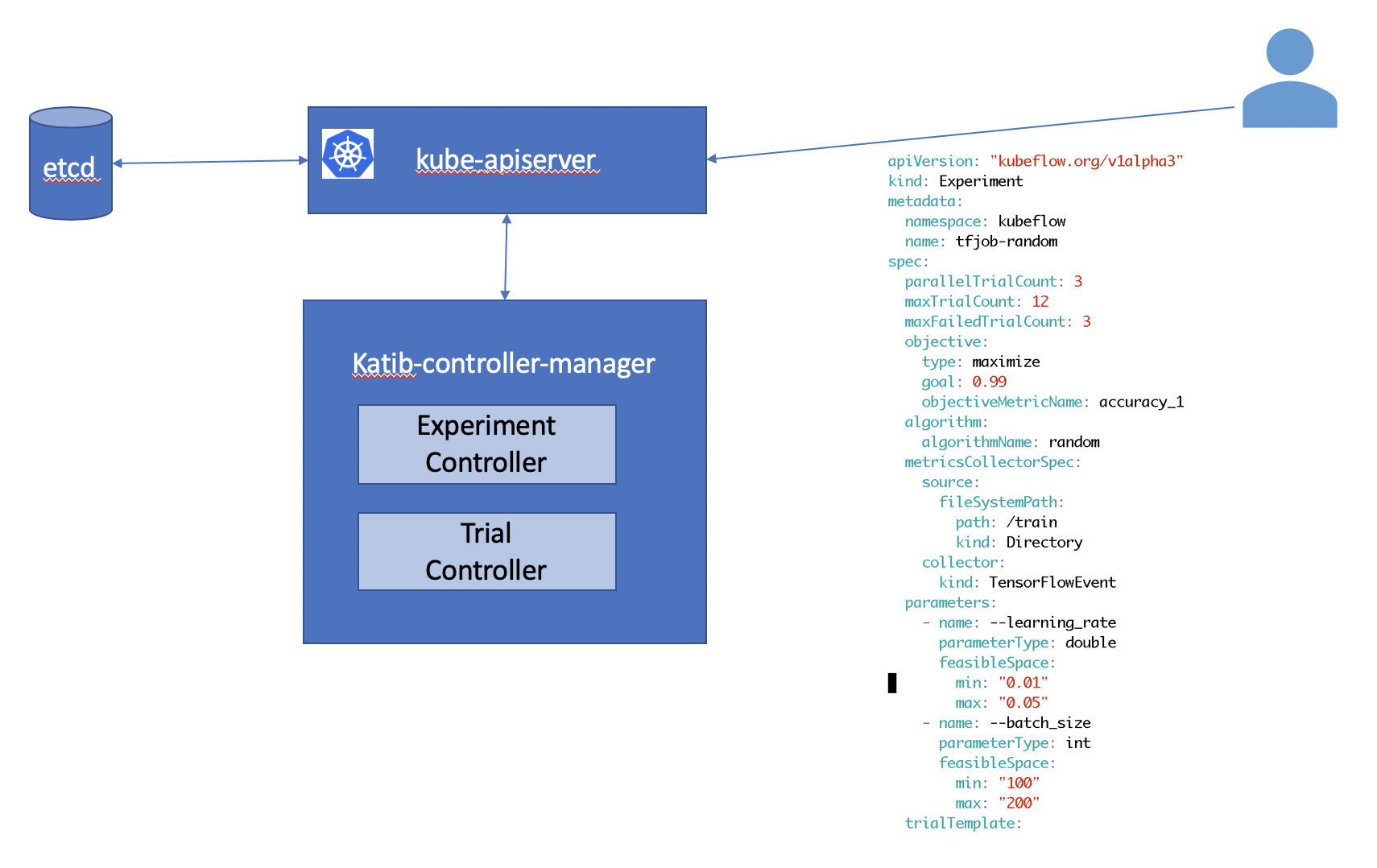
cd $HOME/tutorial/examples/v1alpha3
kubectl apply -f tfjob-random.yaml
Sample Output
experiment.kubeflow.org/tfjob-random createdCheck that the Experiment tfjob-random has started.
kubectl -n kubeflow get experiment
Sample Output
NAME STATUS AGE tfjob-random Running 98sCheck the details of the Experiment tfjob-random
kubectl -n kubeflow get experiment tfjob-random -o json
Sample Output
{
"apiVersion": "kubeflow.org/v1alpha3",
"kind": "Experiment",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"kubeflow.org/v1alpha3\",\"kind\":\"Experiment\",\"metadata\":{\"annotations\":{},\"name\":\"tfjob-random\",\"namespace\":\"kubeflow\"},\"spec\":{\"algorithm\":{\"algorithmName\":\"random\"},\"maxFailedTrialCount\":3,\"maxTrialCount\":12,\"metricsCollectorSpec\":{\"collector\":{\"kind\":\"TensorFlowEvent\"},\"source\":{\"fileSystemPath\":{\"kind\":\"Directory\",\"path\":\"/train\"}}},\"objective\":{\"goal\":0.99,\"objectiveMetricName\":\"accuracy_1\",\"type\":\"maximize\"},\"parallelTrialCount\":3,\"parameters\":[{\"feasibleSpace\":{\"max\":\"0.05\",\"min\":\"0.01\"},\"name\":\"--learning_rate\",\"parameterType\":\"double\"},{\"feasibleSpace\":{\"max\":\"200\",\"min\":\"100\"},\"name\":\"--batch_size\",\"parameterType\":\"int\"}],\"trialTemplate\":{\"goTemplate\":{\"rawTemplate\":\"apiVersion: \\\"kubeflow.org/v1\\\"\\nkind: TFJob\\nmetadata:\\n name: {{.Trial}}\\n namespace: {{.NameSpace}}\\nspec:\\n tfReplicaSpecs:\\n Worker:\\n replicas: 1 \\n restartPolicy: OnFailure\\n template:\\n spec:\\n containers:\\n - name: tensorflow \\n image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0\\n imagePullPolicy: IfNotPresent\\n command:\\n - \\\"python\\\"\\n - \\\"/var/tf_mnist/mnist_with_summaries.py\\\"\\n - \\\"--log_dir=/train/metrics\\\"\\n {{- with .HyperParameters}}\\n {{- range .}}\\n - \\\"{{.Name}}={{.Value}}\\\"\\n {{- end}}\\n {{- end}}\"}}}}\n"
},
"creationTimestamp": "2019-10-27T02:46:02Z",
"finalizers": [
"update-prometheus-metrics"
],
"generation": 2,
"name": "tfjob-random",
"namespace": "kubeflow",
"resourceVersion": "21979",
"selfLink": "/apis/kubeflow.org/v1alpha3/namespaces/kubeflow/experiments/tfjob-random",
"uid": "e9f888cb-f863-11e9-88ef-080027c5bc64"
},
"spec": {
"algorithm": {
"algorithmName": "random",
"algorithmSettings": null
},
"maxFailedTrialCount": 3,
"maxTrialCount": 12,
"metricsCollectorSpec": {
"collector": {
"kind": "TensorFlowEvent"
},
"source": {
"fileSystemPath": {
"kind": "Directory",
"path": "/train"
}
}
},
"objective": {
"goal": 0.99,
"objectiveMetricName": "accuracy_1",
"type": "maximize"
},
"parallelTrialCount": 3,
"parameters": [
{
"feasibleSpace": {
"max": "0.05",
"min": "0.01"
},
"name": "--learning_rate",
"parameterType": "double"
},
{
"feasibleSpace": {
"max": "200",
"min": "100"
},
"name": "--batch_size",
"parameterType": "int"
}
],
"trialTemplate": {
"goTemplate": {
"rawTemplate": "apiVersion: \"kubeflow.org/v1\"\nkind: TFJob\nmetadata:\n name: {{.Trial}}\n namespace: {{.NameSpace}}\nspec:\n tfReplicaSpecs:\n Worker:\n replicas: 1 \n restartPolicy: OnFailure\n template:\n spec:\n containers:\n - name: tensorflow \n image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0\n imagePullPolicy: IfNotPresent\n command:\n - \"python\"\n - \"/var/tf_mnist/mnist_with_summaries.py\"\n - \"--log_dir=/train/metrics\"\n {{- with .HyperParameters}}\n {{- range .}}\n - \"{{.Name}}={{.Value}}\"\n {{- end}}\n {{- end}}"
}
}
},
"status": {
"completionTime": null,
"conditions": [
{
"lastTransitionTime": "2019-10-27T02:46:02Z",
"lastUpdateTime": "2019-10-27T02:46:02Z",
"message": "Experiment is created",
"reason": "ExperimentCreated",
"status": "True",
"type": "Created"
}
],
"currentOptimalTrial": {
"observation": {
"metrics": null
},
"parameterAssignments": null
},
"startTime": "2019-10-27T02:46:02Z"
}
}
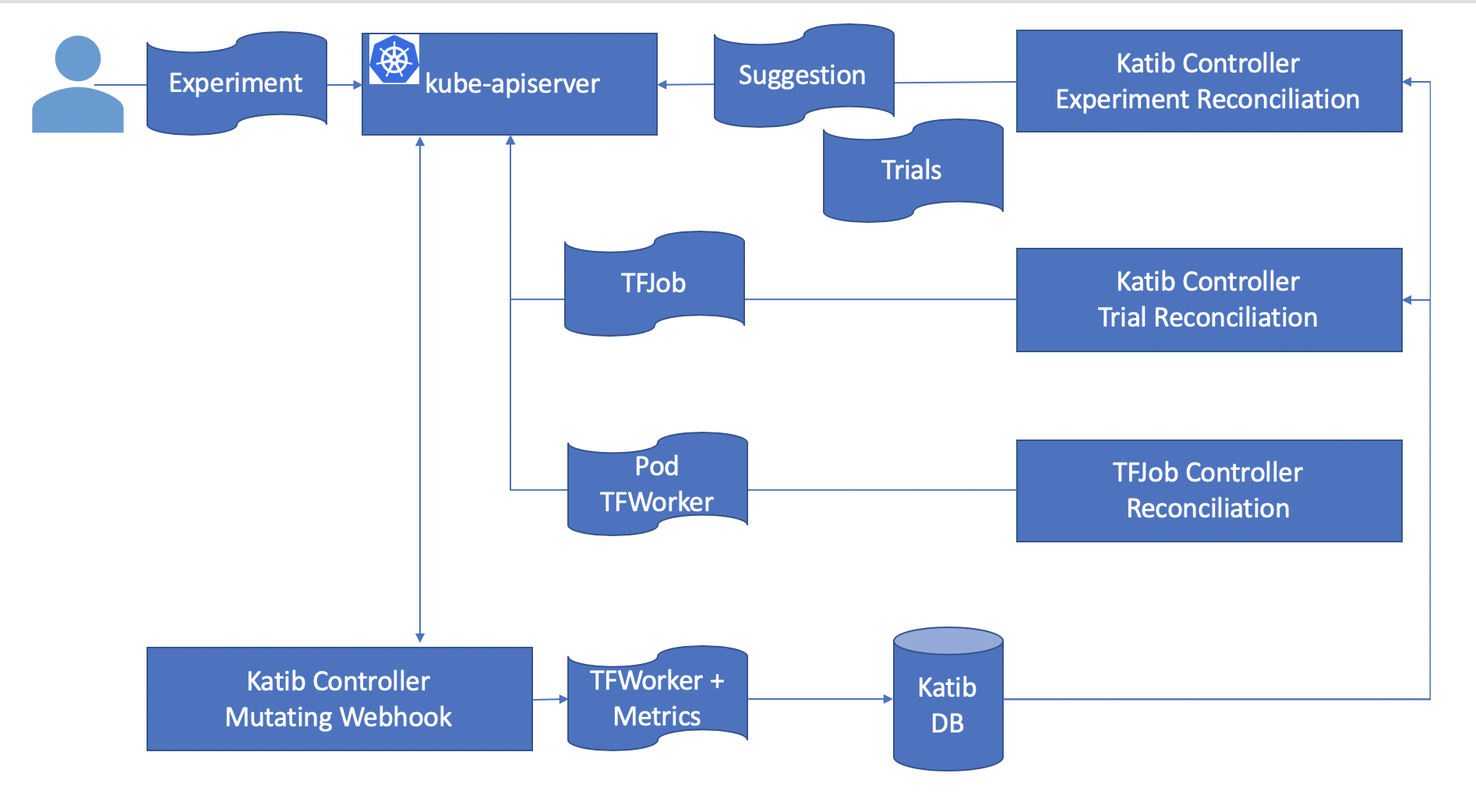
Under the hood, Katib controller is looping in a reconcile loop to satisfy this Experiment request.
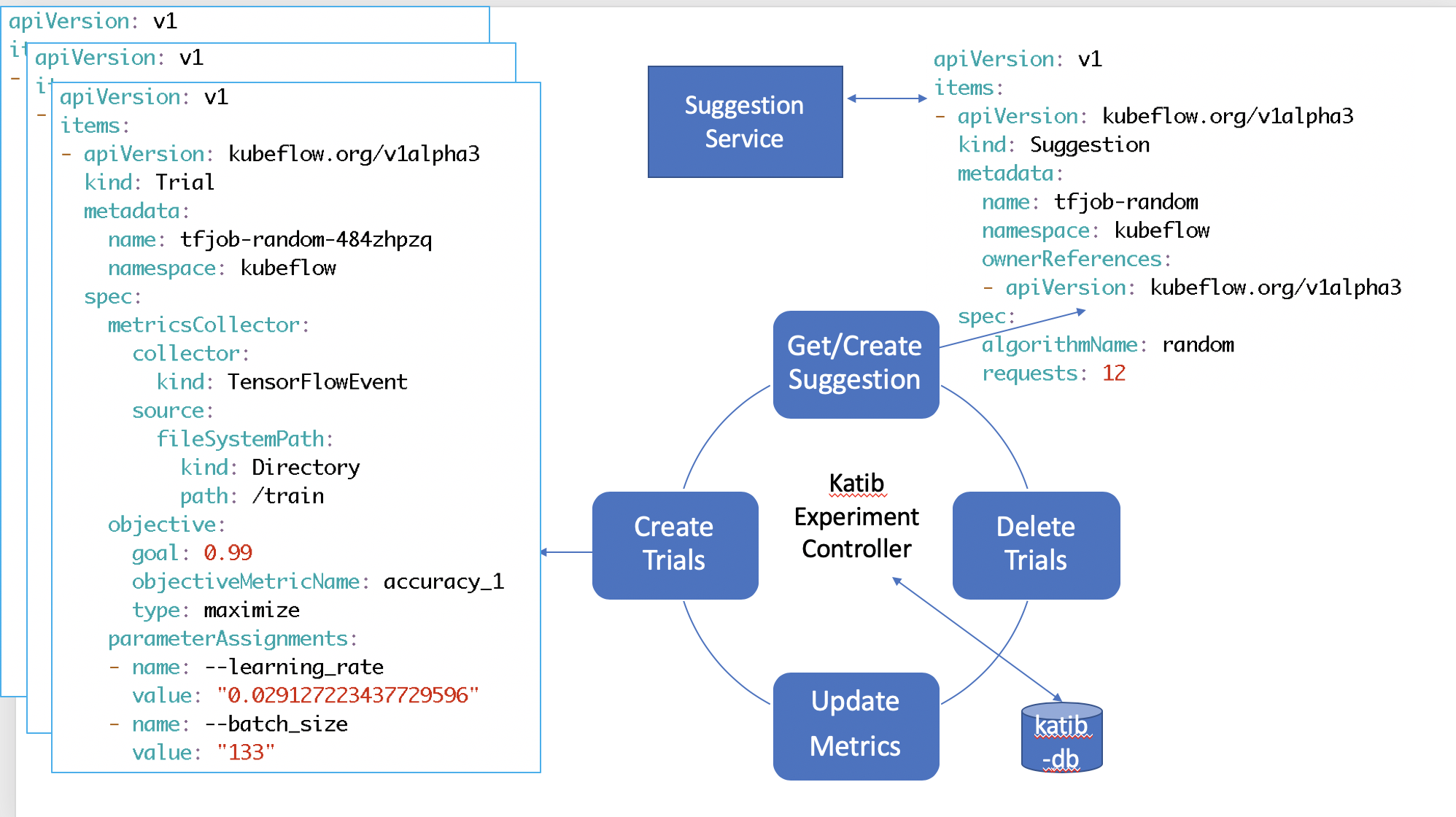
Suggestions
You can see Katib creating Suggestions using the random algorithm.
kubectl -n kubeflow get suggestions tfjob-random -o yaml
Sample Output - before suggestions are ready
apiVersion: kubeflow.org/v1alpha3
kind: Suggestion
metadata:
creationTimestamp: "2019-10-27T02:57:58Z"
generation: 1
name: tfjob-random
namespace: kubeflow
ownerReferences:
- apiVersion: kubeflow.org/v1alpha3
blockOwnerDeletion: true
controller: true
kind: Experiment
name: tfjob-random
uid: 94e07a51-f865-11e9-88ef-080027c5bc64
resourceVersion: "24296"
selfLink: /apis/kubeflow.org/v1alpha3/namespaces/kubeflow/suggestions/tfjob-random
uid: 94e5930d-f865-11e9-88ef-080027c5bc64
spec:
algorithmName: random
requests: 3
status:
conditions:
- lastTransitionTime: "2019-10-27T02:57:58Z"
lastUpdateTime: "2019-10-27T02:57:58Z"
message: Suggestion is created
reason: SuggestionCreated
status: "True"
type: Created
- lastTransitionTime: "2019-10-27T02:57:58Z"
lastUpdateTime: "2019-10-27T02:57:58Z"
message: Deployment is not ready
reason: DeploymentNotReady
status: "False"
type: DeploymentReady
startTime: "2019-10-27T02:57:58Z"
We now have a Suggestion resource created. The Katib Suggestion Service takes control and generates a deployment to run the specified Suggestion.
 The suggestion service provides suggestions based on the current state of the system. On each new suggestion request, it reevaluates and provides the next best set of suggestions.
The suggestion service provides suggestions based on the current state of the system. On each new suggestion request, it reevaluates and provides the next best set of suggestions.
Sample Output - after suggestions are ready
apiVersion: v1
items:
- apiVersion: kubeflow.org/v1alpha3
kind: Suggestion
metadata:
creationTimestamp: "2019-10-27T02:57:58Z"
generation: 10
name: tfjob-random
namespace: kubeflow
ownerReferences:
- apiVersion: kubeflow.org/v1alpha3
blockOwnerDeletion: true
controller: true
kind: Experiment
name: tfjob-random
uid: 94e07a51-f865-11e9-88ef-080027c5bc64
resourceVersion: "25675"
selfLink: /apis/kubeflow.org/v1alpha3/namespaces/kubeflow/suggestions/tfjob-random
uid: 94e5930d-f865-11e9-88ef-080027c5bc64
spec:
algorithmName: random
requests: 12
status:
conditions:
- lastTransitionTime: "2019-10-27T02:57:58Z"
lastUpdateTime: "2019-10-27T02:57:58Z"
message: Suggestion is created
reason: SuggestionCreated
status: "True"
type: Created
- lastTransitionTime: "2019-10-27T02:58:16Z"
lastUpdateTime: "2019-10-27T02:58:16Z"
message: Deployment is ready
reason: DeploymentReady
status: "True"
type: DeploymentReady
- lastTransitionTime: "2019-10-27T02:59:16Z"
lastUpdateTime: "2019-10-27T02:59:16Z"
message: Suggestion is running
reason: SuggestionRunning
status: "True"
type: Running
startTime: "2019-10-27T02:57:58Z"
suggestionCount: 12
suggestions:
- name: tfjob-random-npjpbgmd
parameterAssignments:
- name: --learning_rate
value: "0.03684477847537918"
- name: --batch_size
value: "112"
- name: tfjob-random-mmc8dqvq
parameterAssignments:
- name: --learning_rate
value: "0.010960280128777096"
- name: --batch_size
value: "126"
- name: tfjob-random-6h7229dt
parameterAssignments:
- name: --learning_rate
value: "0.011672960430260329"
- name: --batch_size
value: "181"
- name: tfjob-random-hfzrfh8j
parameterAssignments:
- name: --learning_rate
value: "0.03510831325099869"
- name: --batch_size
value: "156"
- name: tfjob-random-7kg9zhrt
parameterAssignments:
- name: --learning_rate
value: "0.02709470325001432"
- name: --batch_size
value: "157"
- name: tfjob-random-gng5qx9x
parameterAssignments:
- name: --learning_rate
value: "0.021854230935173045"
- name: --batch_size
value: "148"
- name: tfjob-random-5sfxkhmc
parameterAssignments:
- name: --learning_rate
value: "0.011053371330636894"
- name: --batch_size
value: "131"
- name: tfjob-random-7bzhkvvd
parameterAssignments:
- name: --learning_rate
value: "0.039025808494984444"
- name: --batch_size
value: "139"
- name: tfjob-random-xjm458qc
parameterAssignments:
- name: --learning_rate
value: "0.023093126743054533"
- name: --batch_size
value: "105"
- name: tfjob-random-zb89h929
parameterAssignments:
- name: --learning_rate
value: "0.017877859019641958"
- name: --batch_size
value: "192"
- name: tfjob-random-wqglhpqj
parameterAssignments:
- name: --learning_rate
value: "0.018670804338535255"
- name: --batch_size
value: "191"
- name: tfjob-random-484zhpzq
parameterAssignments:
- name: --learning_rate
value: "0.029127223437729596"
- name: --batch_size
value: "133"
Trials
Once the suggestions are ready, Katib Trail controller is ready to run the trials.
Each Trial evaluates the performance for the suggested hyperparameter vector and records the performance in the metric collector.
You can see Katib creating multiple Trials.
kubectl -n kubeflow get trials
Sample Output
NAME TYPE STATUS AGE tfjob-random-5xq64qwz Created True 25s tfjob-random-h9l2h54d Created True 25s tfjob-random-pf5htw5f Created True 25s
Each trial starts a TFJob resource.
kubectl -n kubeflow get tfjobs
Sample Output
NAME TYPE STATUS AGE tfjob-random-5xq64qwz Created True 25s tfjob-random-h9l2h54d Created True 25s tfjob-random-pf5htw5f Created True 25s
Each TFJob creates a Worker pod to run the trial.
kubectl -n kubeflow get po -l controller-name=tf-operator
Sample Output
NAME READY STATUS RESTARTS AGE
tfjob-random-484zhpzq-worker-0 2/2 Running 0 39s
tfjob-random-wqglhpqj-worker-0 2/2 Running 0 40s
tfjob-random-zb89h929-worker-0 2/2 Running 0 41s
Metric Collection
When we talked about the Kubernetes architecture we briefly mentioned how a user creates resources using the Kubernetes API server and how the Kubernetes API server stores this data in etcd.

In reality, there are several stages between the Kubernetes API server receiving a request before it is accepted. In particular, there are two common extension points where external controllers can do additional tasks. These are mutating admission controllers and validating admission controllers. Katib controller registers itself as both a mutating and validating controller.
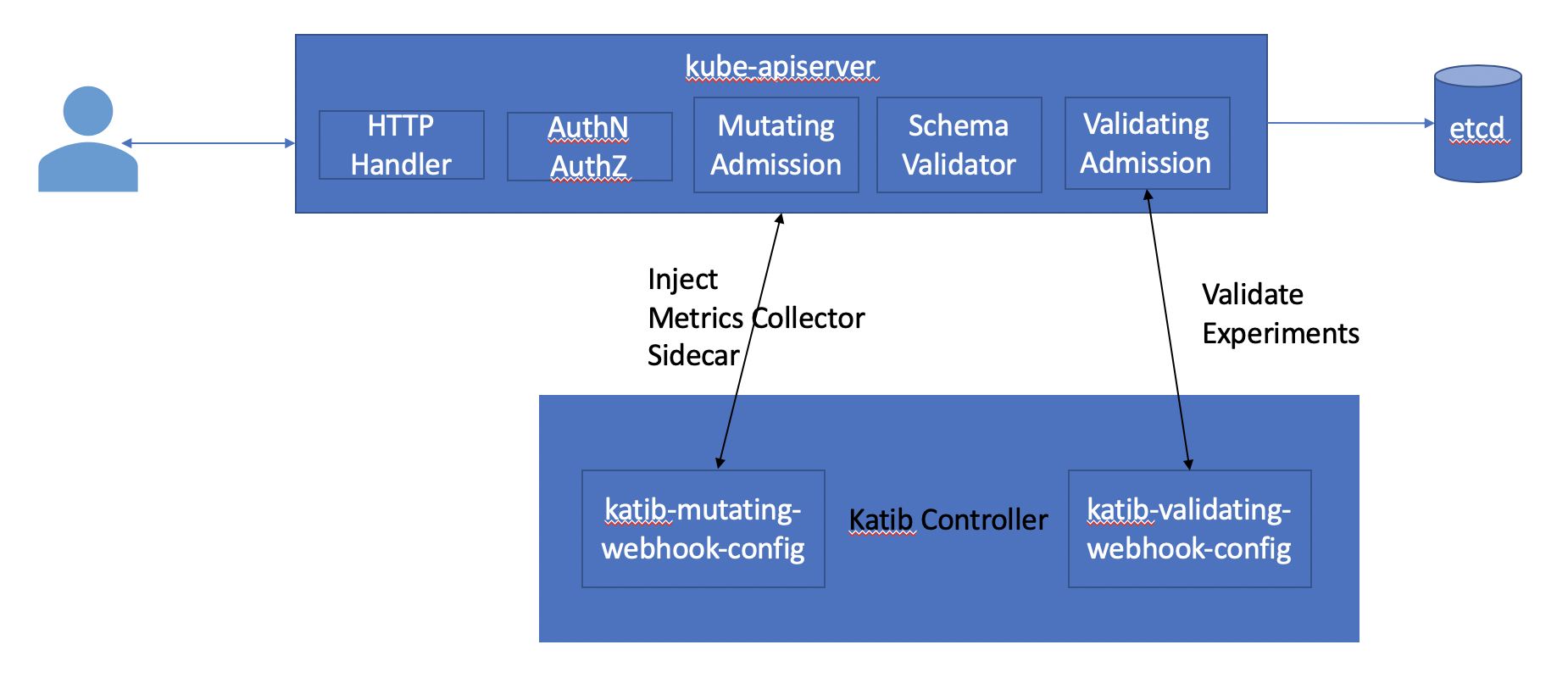
You can see the webhooks as follows.
kubectl get MutatingWebhookConfiguration
Sample Output
NAME CREATED AT
katib-mutating-webhook-config 2019-10-26T21:00:30Z
kubectl get ValidatingWebhookConfiguration
Sample Output
NAME CREATED AT
katib-validating-webhook-config 2019-10-26T21:00:30Z
The mutating webhook looks at Katib configuration and injects a side car container to the Trial jobs/pods. You can see the configurations as follows.
kubectl -n kubeflow get cm katib-config -o yaml
Sample Output
apiVersion: v1
data:
metrics-collector-sidecar: |-
{
"StdOut": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/file-metrics-collector:v0.7.0"
},
"File": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/file-metrics-collector:v0.7.0"
},
"TensorFlowEvent": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0"
}
}
suggestion: |-
{
"random": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/suggestion-hyperopt:v0.7.0"
},
"grid": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/suggestion-chocolate:v0.7.0"
},
"hyperband": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/suggestion-hyperband:v0.7.0"
},
"bayesianoptimization": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/suggestion-skopt:v0.7.0"
},
"tpe": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/suggestion-hyperopt:v0.7.0"
},
"nasrl": {
"image": "gcr.io/kubeflow-images-public/katib/v1alpha3/suggestion-nasrl:v0.7.0"
}
}
kind: ConfigMap
We can see the metrics-collector container injected into the TFJob worker pod.
kubectl -n kubeflow describe po -l controller-name=tf-operator
Sample Output
Name: tfjob-random-g4p7jx5b-worker-0
Namespace: kubeflow
Priority: 0
PriorityClassName: <none>
Node: katib/10.0.2.15
Start Time: Tue, 29 Oct 2019 18:37:20 +0000
Labels: controller-name=tf-operator
group-name=kubeflow.org
job-name=tfjob-random-g4p7jx5b
job-role=master
tf-job-name=tfjob-random-g4p7jx5b
tf-replica-index=0
tf-replica-type=worker
Annotations: <none>
Status: Pending
IP:
Controlled By: TFJob/tfjob-random-g4p7jx5b
Containers:
tensorflow:
Container ID:
Image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
Image ID:
Port: 2222/TCP
Host Port: 0/TCP
Command:
python
/var/tf_mnist/mnist_with_summaries.py
--log_dir=/train/metrics
--learning_rate=0.044867652686667765
--batch_size=179
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/train from metrics-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-mskhc (ro)
metrics-collector:
Container ID:
Image: gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0
Image ID:
Port: <none>
Host Port: <none>
Args:
-t
tfjob-random-g4p7jx5b
-m
accuracy_1
-s
katib-manager.kubeflow:6789
-path
/train
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/train from metrics-volume (rw)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-mskhc:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-mskhc
Optional: false
metrics-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4s default-scheduler Successfully assigned kubeflow/tfjob-random-g4p7jx5b-worker-0 to katib
Normal Pulled 2s kubelet, katib Container image "gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0" already present on machine
Normal Created 2s kubelet, katib Created container tensorflow
Normal Started 1s kubelet, katib Started container tensorflow
Normal Pulled 1s kubelet, katib Container image "gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0" already present on machine
Normal Created 1s kubelet, katib Created container metrics-collector
Normal Started 1s kubelet, katib Started container metrics-collector
Name: tfjob-random-jcdvtfdf-worker-0
Namespace: kubeflow
Priority: 0
PriorityClassName: <none>
Node: katib/10.0.2.15
Start Time: Tue, 29 Oct 2019 18:35:44 +0000
Labels: controller-name=tf-operator
group-name=kubeflow.org
job-name=tfjob-random-jcdvtfdf
job-role=master
tf-job-name=tfjob-random-jcdvtfdf
tf-replica-index=0
tf-replica-type=worker
Annotations: <none>
Status: Running
IP: 192.168.0.231
Controlled By: TFJob/tfjob-random-jcdvtfdf
Containers:
tensorflow:
Container ID: docker://2792566751a57a6ab804621a9ec8b56e29ced44ddaceb6e395cd4fb8d7b0f7d6
Image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
Image ID: docker-pullable://gcr.io/kubeflow-ci/tf-mnist-with-summaries@sha256:5c3181c3a97bc6f88fab204d4ac19ea12413b192953e21dc0ed07e7b821ddbe2
Port: 2222/TCP
Host Port: 0/TCP
Command:
python
/var/tf_mnist/mnist_with_summaries.py
--log_dir=/train/metrics
--learning_rate=0.025430765523205827
--batch_size=140
State: Running
Started: Tue, 29 Oct 2019 18:35:46 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/train from metrics-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-mskhc (ro)
metrics-collector:
Container ID: docker://4109a92753bdfddb2aa9dd4f866fcddb068016e2a65b24a321ac0ac832fac48f
Image: gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0
Image ID: docker-pullable://gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector@sha256:d7c8fa8147f99ebb563c4d59fc6c333f96684f1598cce2f7eae629a878671656
Port: <none>
Host Port: <none>
Args:
-t
tfjob-random-jcdvtfdf
-m
accuracy_1
-s
katib-manager.kubeflow:6789
-path
/train
State: Running
Started: Tue, 29 Oct 2019 18:35:46 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/train from metrics-volume (rw)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-mskhc:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-mskhc
Optional: false
metrics-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 99s default-scheduler Successfully assigned kubeflow/tfjob-random-jcdvtfdf-worker-0 to katib
Normal Pulled 97s kubelet, katib Container image "gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0" already present on machine
Normal Created 97s kubelet, katib Created container tensorflow
Normal Started 97s kubelet, katib Started container tensorflow
Normal Pulled 97s kubelet, katib Container image "gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0" already present on machine
Normal Created 97s kubelet, katib Created container metrics-collector
Normal Started 97s kubelet, katib Started container metrics-collector
Name: tfjob-random-r66tzmjr-worker-0
Namespace: kubeflow
Priority: 0
PriorityClassName: <none>
Node: katib/10.0.2.15
Start Time: Tue, 29 Oct 2019 18:35:43 +0000
Labels: controller-name=tf-operator
group-name=kubeflow.org
job-name=tfjob-random-r66tzmjr
job-role=master
tf-job-name=tfjob-random-r66tzmjr
tf-replica-index=0
tf-replica-type=worker
Annotations: <none>
Status: Running
IP: 192.168.0.230
Controlled By: TFJob/tfjob-random-r66tzmjr
Containers:
tensorflow:
Container ID: docker://b3836fc16b83e82b3c3cad90472eeb079762f320270c834038d4a58f845f45b1
Image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
Image ID: docker-pullable://gcr.io/kubeflow-ci/tf-mnist-with-summaries@sha256:5c3181c3a97bc6f88fab204d4ac19ea12413b192953e21dc0ed07e7b821ddbe2
Port: 2222/TCP
Host Port: 0/TCP
Command:
python
/var/tf_mnist/mnist_with_summaries.py
--log_dir=/train/metrics
--learning_rate=0.04503686583590331
--batch_size=120
State: Running
Started: Tue, 29 Oct 2019 18:35:45 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/train from metrics-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-mskhc (ro)
metrics-collector:
Container ID: docker://a94b366df6c6e3e318be7b9a72e92c26e988167338aacae68498ef68662eb619
Image: gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0
Image ID: docker-pullable://gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector@sha256:d7c8fa8147f99ebb563c4d59fc6c333f96684f1598cce2f7eae629a878671656
Port: <none>
Host Port: <none>
Args:
-t
tfjob-random-r66tzmjr
-m
accuracy_1
-s
katib-manager.kubeflow:6789
-path
/train
State: Running
Started: Tue, 29 Oct 2019 18:35:45 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/train from metrics-volume (rw)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-mskhc:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-mskhc
Optional: false
metrics-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 100s default-scheduler Successfully assigned kubeflow/tfjob-random-r66tzmjr-worker-0 to katib
Normal Pulled 99s kubelet, katib Container image "gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0" already present on machine
Normal Created 99s kubelet, katib Created container tensorflow
Normal Started 98s kubelet, katib Started container tensorflow
Normal Pulled 98s kubelet, katib Container image "gcr.io/kubeflow-images-public/katib/v1alpha3/tfevent-metrics-collector:v0.7.0" already present on machine
Normal Created 98s kubelet, katib Created container metrics-collector
Normal Started 98s kubelet, katib Started container metrics-collector
Experiment Completion
Once the Trials created by Katib are complete, the Experiment enters a completed state.
Check the completion status of the Experiment tfjob-random
kubectl -n kubeflow get experiment tfjob-random -o json
Sample Output
You can observe the status of this experiment under the status field of the output.
You can also see that Katib has cleaned up the Trial worker pods.
kubectl -n kubeflow get pods
Sample Output
NAME READY STATUS RESTARTS AGE
katib-controller-7665868558-nfghw 1/1 Running 1 21m
katib-db-594756f779-dxttq 1/1 Running 0 21m
katib-manager-769b7bcbfb-7vvgx 1/1 Running 0 21m
katib-ui-854969c97-tl4wg 1/1 Running 0 21m
pytorch-operator-794899d49b-ww59g 1/1 Running 0 21m
tf-job-operator-7b589f5f5f-fpr2p 1/1 Running 0 21m
tfjob-example-random-6d68b59ccd-fcn8f 1/1 Running 0 15m
In summary all you need to know about is to create the Experiment specification. Katib magically does the rest for you.
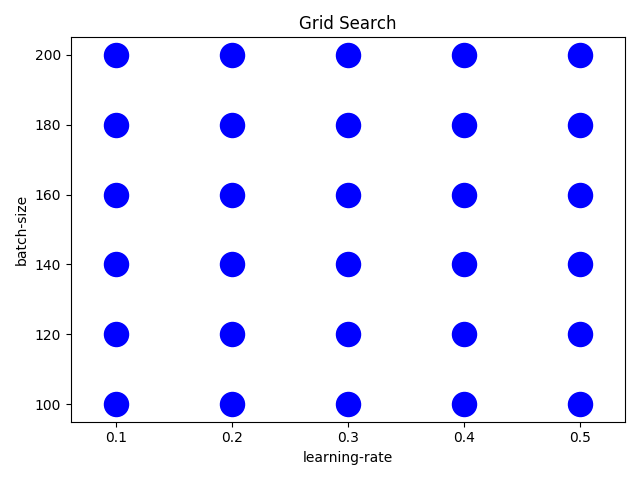
Grid Search
Grid search is also a black box algorithm similar to Random search. It assumes nothing about the model and each trial can be run in parallel.
Grid search does an exhaustive search over the entire search space. Ideally you want the search to be uniform across your entire search space. The following picture shows an example search with step size 10 for the batch size.
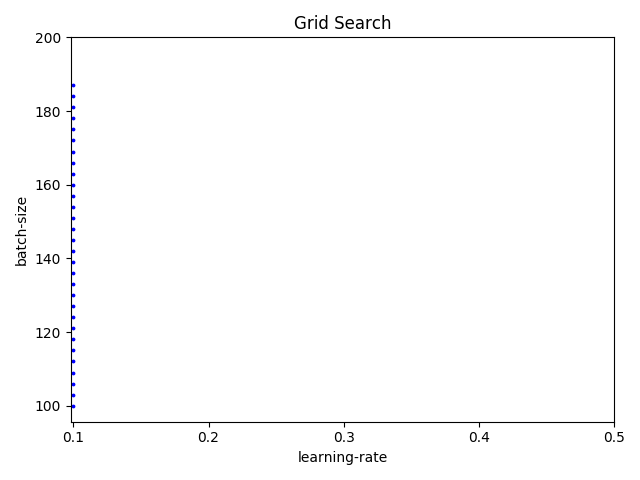
However depending on the search space and the parameters you chose, the grid algorithm may end up not covering a lot of ground in one hyperparameter space. For example for the same example above, if you choose a step size of 3 instead of 10, you get the following coverage in 30 iterations.
So if you want a generic baseline, it is always a good idea to start with a Random search.
Now let us create a grid search experiment using Katib.
Experiment
Let us start by creating an experiment.
Grid search experiment
apiVersion: "kubeflow.org/v1alpha3"
kind: Experiment
metadata:
namespace: kubeflow
name: tfjob-grid
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy_1
algorithm:
algorithmName: grid
metricsCollectorSpec:
source:
fileSystemPath:
path: /train
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: --learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
step: "0.001"
- name: --batch_size
parameterType: int
feasibleSpace:
min: "100"
max: "200"
step: "20"
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: "kubeflow.org/v1"
kind: TFJob
metadata:
name: {{.Trial}}
namespace: {{.NameSpace}}
spec:
tfReplicaSpecs:
Worker:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
imagePullPolicy: IfNotPresent
command:
- "python"
- "/var/tf_mnist/mnist_with_summaries.py"
- "--log_dir=/train/metrics"
{{- with .HyperParameters}}
{{- range .}}
- "{{.Name}}={{.Value}}"
{{- end}}
{{- end}}
There are two changes in this yaml compared to the random search. First we set algorithmName: grid instead of algorithmName: random. Second we set the step sizes using step: "0.001" and step: "20".
Create this experiment as follows.
cd $HOME/tutorial/examples/v1alpha3
kubectl apply -f tfjob-grid.yaml
Sample Output
experiment.kubeflow.org/tfjob-grid created
Check that the Experiment tfjob-grid has started.
kubectl -n kubeflow get experiment
Sample Output
NAME STATUS AGE tfjob-grid Running 98sCheck the details of the Experiment tfjob-grid
kubectl -n kubeflow get experiment tfjob-grid -o yaml
Sample Output
apiVersion: kubeflow.org/v1alpha3
kind: Experiment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"kubeflow.org/v1alpha3","kind":"Experiment","metadata":{"annotations":{},"name":"tfjob-grid","namespace":"kubeflow"},"spec":{"algorithm":{"algorithmName":"grid"},"maxFailedTrialCount":3,"maxTrialCount":12,"metricsCollectorSpec":{"collector":{"kind":"TensorFlowEvent"},"source":{"fileSystemPath":{"kind":"Directory","path":"/train"}}},"objective":{"goal":0.99,"objectiveMetricName":"accuracy_1","type":"maximize"},"parallelTrialCount":3,"parameters":[{"feasibleSpace":{"max":"0.05","min":"0.01","step":"0.001"},"name":"--learning_rate","parameterType":"double"},{"feasibleSpace":{"max":"200","min":"100","step":"1"},"name":"--batch_size","parameterType":"int"}],"trialTemplate":{"goTemplate":{"rawTemplate":"apiVersion: \"kubeflow.org/v1\"\nkind: TFJob\nmetadata:\n name: {{.Trial}}\n namespace: {{.NameSpace}}\nspec:\n tfReplicaSpecs:\n Worker:\n replicas: 1 \n restartPolicy: OnFailure\n template:\n spec:\n containers:\n - name: tensorflow \n image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0\n imagePullPolicy: IfNotPresent\n command:\n - \"python\"\n - \"/var/tf_mnist/mnist_with_summaries.py\"\n - \"--log_dir=/train/metrics\"\n {{- with .HyperParameters}}\n {{- range .}}\n - \"{{.Name}}={{.Value}}\"\n {{- end}}\n {{- end}}"}}}}
creationTimestamp: "2019-10-27T17:32:38Z"
finalizers:
- update-prometheus-metrics
generation: 2
name: tfjob-grid
namespace: kubeflow
resourceVersion: "153550"
selfLink: /apis/kubeflow.org/v1alpha3/namespaces/kubeflow/experiments/tfjob-grid
uid: c5934b51-f8df-11e9-88ef-080027c5bc64
spec:
algorithm:
algorithmName: grid
algorithmSettings: null
maxFailedTrialCount: 3
maxTrialCount: 12
metricsCollectorSpec:
collector:
kind: TensorFlowEvent
source:
fileSystemPath:
kind: Directory
path: /train
objective:
goal: 0.99
objectiveMetricName: accuracy_1
type: maximize
parallelTrialCount: 3
parameters:
- feasibleSpace:
max: "0.05"
min: "0.01"
step: "0.001"
name: --learning_rate
parameterType: double
- feasibleSpace:
max: "200"
min: "100"
step: "1"
name: --batch_size
parameterType: int
trialTemplate:
goTemplate:
rawTemplate: "apiVersion: \"kubeflow.org/v1\"\nkind: TFJob\nmetadata:\n name:
{{.Trial}}\n namespace: {{.NameSpace}}\nspec:\n tfReplicaSpecs:\n Worker:\n
\ replicas: 1 \n restartPolicy: OnFailure\n template:\n spec:\n
\ containers:\n - name: tensorflow \n image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0\n
\ imagePullPolicy: IfNotPresent\n command:\n -
\"python\"\n - \"/var/tf_mnist/mnist_with_summaries.py\"\n -
\"--log_dir=/train/metrics\"\n {{- with .HyperParameters}}\n
\ {{- range .}}\n - \"{{.Name}}={{.Value}}\"\n {{-
end}}\n {{- end}}"
status:
completionTime: "2019-10-27T17:42:37Z"
conditions:
- lastTransitionTime: "2019-10-27T17:32:38Z"
lastUpdateTime: "2019-10-27T17:32:38Z"
message: Experiment is created
reason: ExperimentCreated
status: "True"
type: Created
- lastTransitionTime: "2019-10-27T17:42:37Z"
lastUpdateTime: "2019-10-27T17:42:37Z"
message: Experiment is running
reason: ExperimentRunning
status: "False"
type: Running
- lastTransitionTime: "2019-10-27T17:42:37Z"
lastUpdateTime: "2019-10-27T17:42:37Z"
message: Experiment has succeeded because max trial count has reached
reason: ExperimentSucceeded
status: "True"
type: Succeeded
currentOptimalTrial:
observation:
metrics:
- name: accuracy_1
value: 0.970499992371
parameterAssignments:
- name: --learning_rate
value: "0.01"
- name: --batch_size
value: "110"
startTime: "2019-10-27T17:32:38Z"
trials: 12
trialsSucceeded: 12
Bayesian Optimization
Model training is an expensive process and each time we want to evaluate a hyperparameter vector, we have to run this process.
This makes grid search very expensive as it is exponential in the number of hyperparameters. Random search may also need many iterations to get to a good hyperparameter vector as it is randomly trying out different options.
Before automatic hyperparameter tuning was wide spread, the common mechanism for finding a good set of hyperparameters was to use Grad Student Descent or Intern Descent. Human reasoning often follows a bayesian model, where we try out something and then iteratively pick what we think is a good next set of values to try. Systems in the real world often fit a probability distribution, like a normal distribution. Bayesian optimization models the hyperparameter vector performance as a distribution, often a Gaussian process. We then try to optimize the performance of this function. We also naturally make the trade off between exploration and exploitation. If the term paper is due tomorrow or if there is a release deadline, we may choose to optimize amongst the known best performing values. If we have a few months to try out different options, we may choose to try out a wider range of values.
Bayesian optimization follows a similar pattern with user configurable parameters to control the amount of exploration vs exploitation. Let us see how this works starting with an example based on the bayes_opt package.
Let us assume that the unknown hyperparameter performance function for our hyperparameter of interest is as follows.
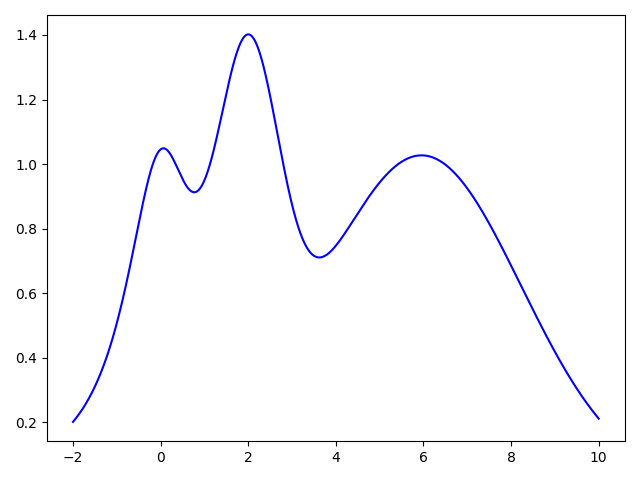
Initially we don't know anything about this function, so let us pick one hyperparameter vector at random and run the model training to evaluate the hyperparameter vector performance.
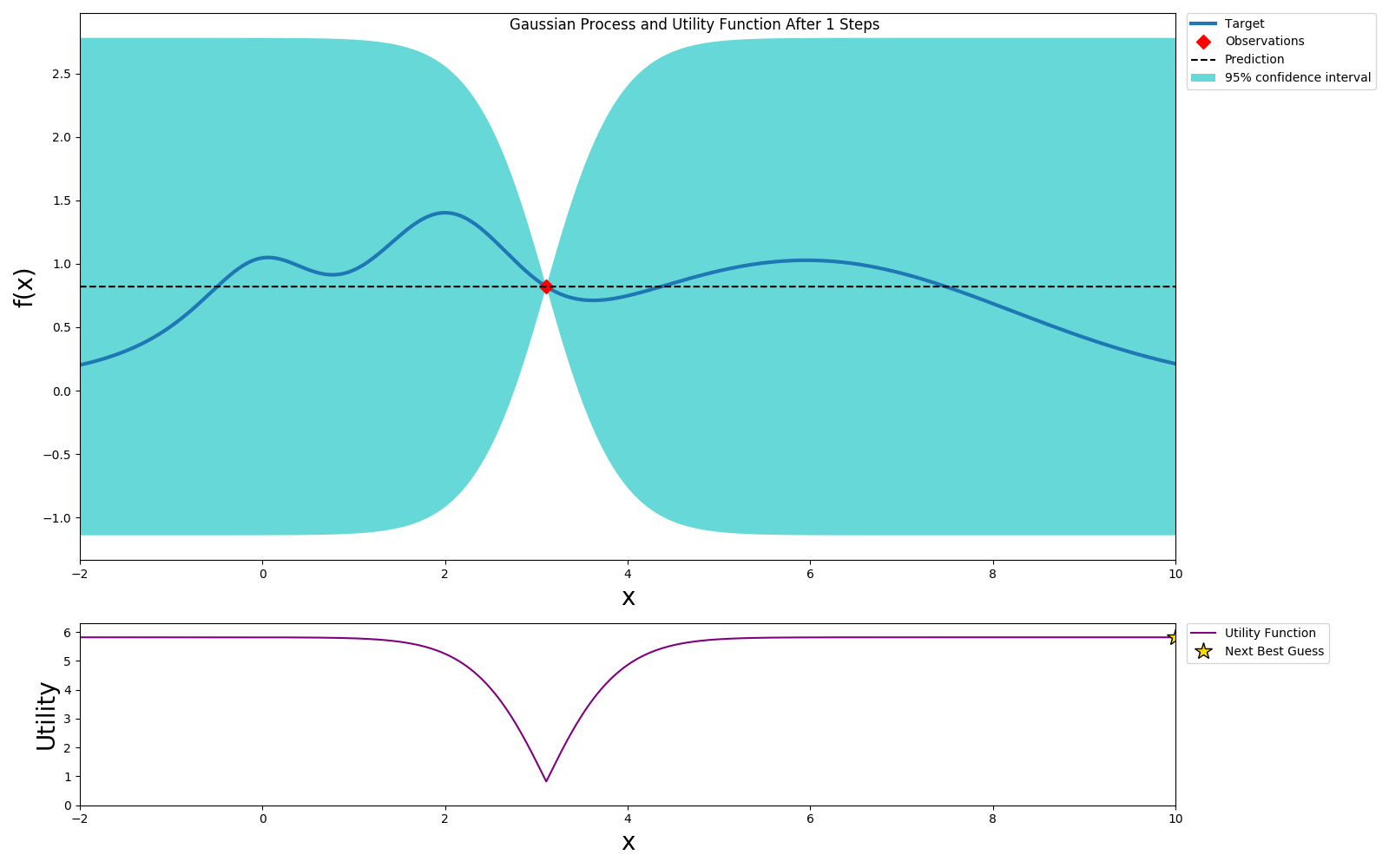
We can use expected improvement(EI) or Upper Confidence Bound(UCB) as the acquisition or utility function and pick a value that will optimize this. In this example we choose UCB as the utility function. UCB provides a way to configure the amount of exploration we want to allow. We choose the optimal value per the utility function and sample this value.
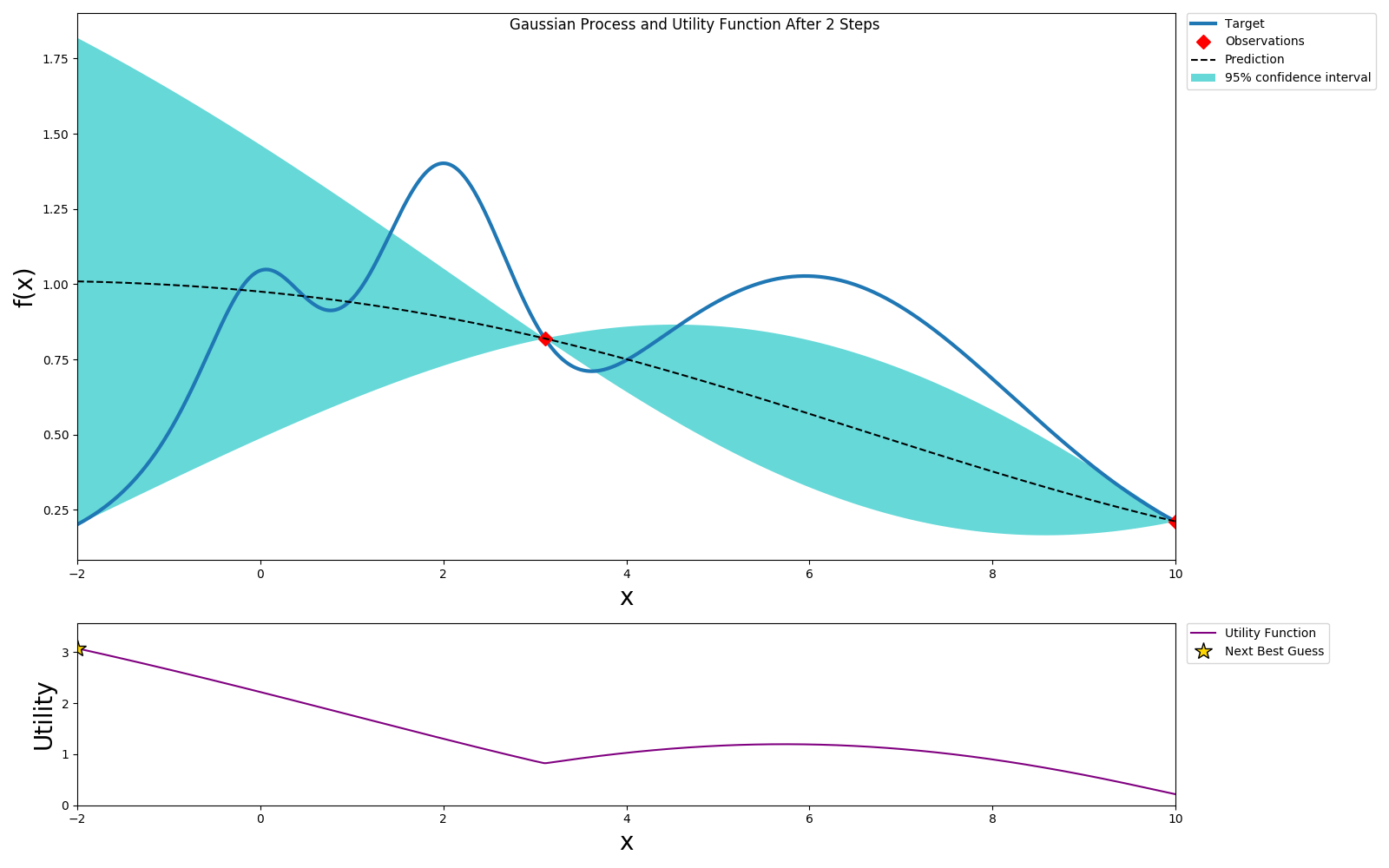
We repeat this process until we've reach the desired accuracy or we've exhausted our budget.
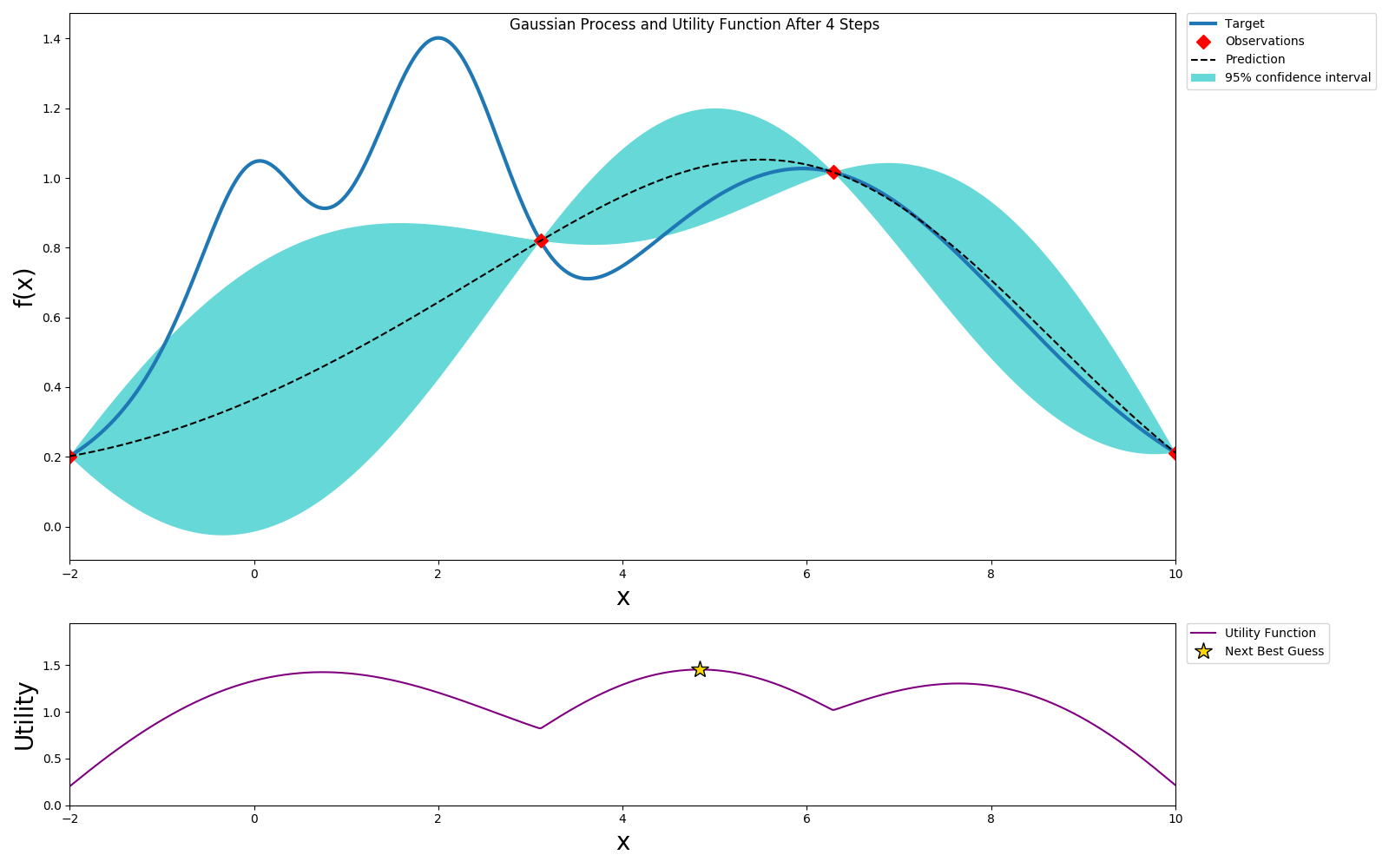
We can get to a globally optimal value pretty quickly
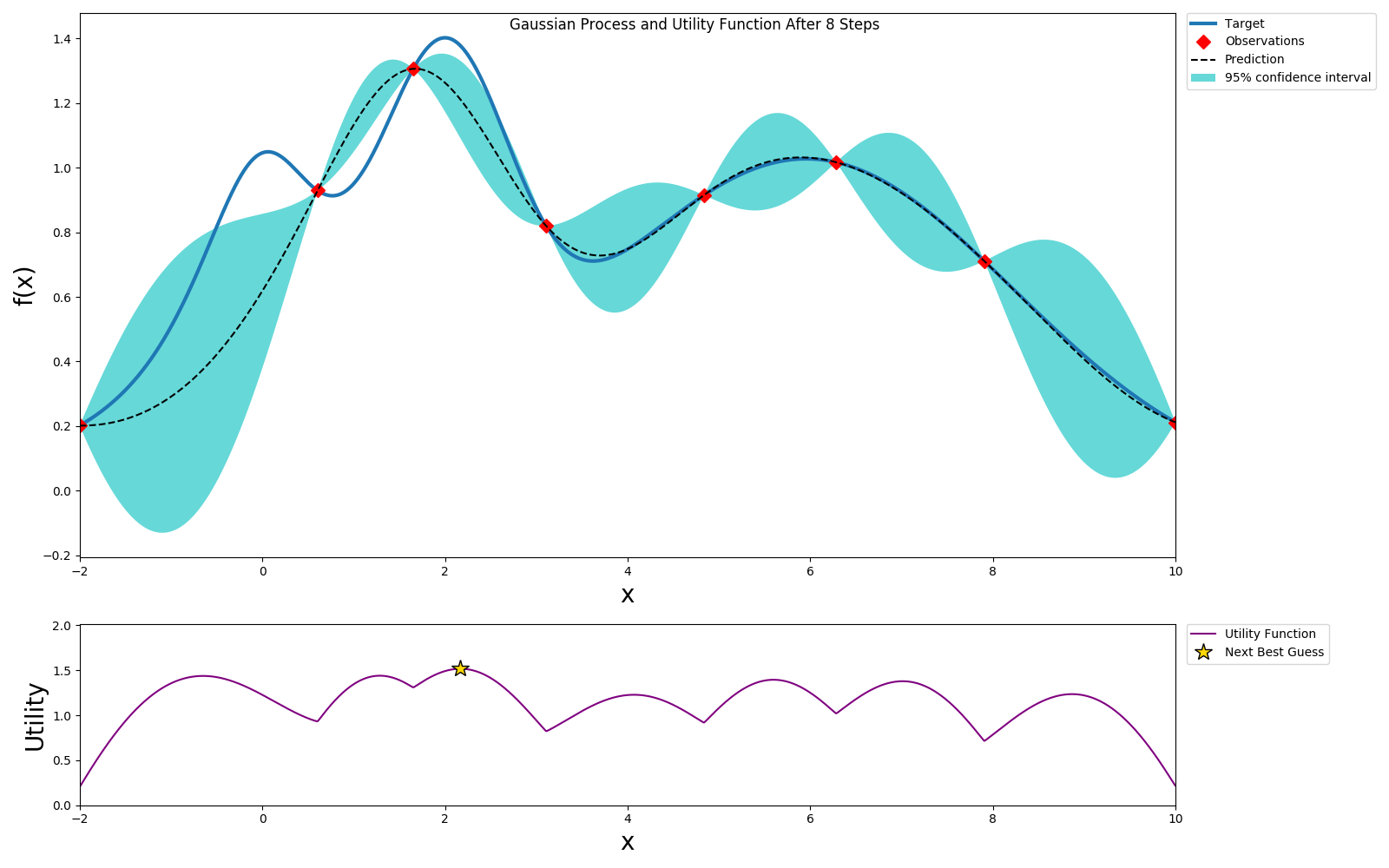
Here we picked an exploration constant of 5. If we repeated the same experiment with it set to 1, we can see that the algorithm does not explore too much and selects a local maximum instead of a global maximum, but also it converges much faster.
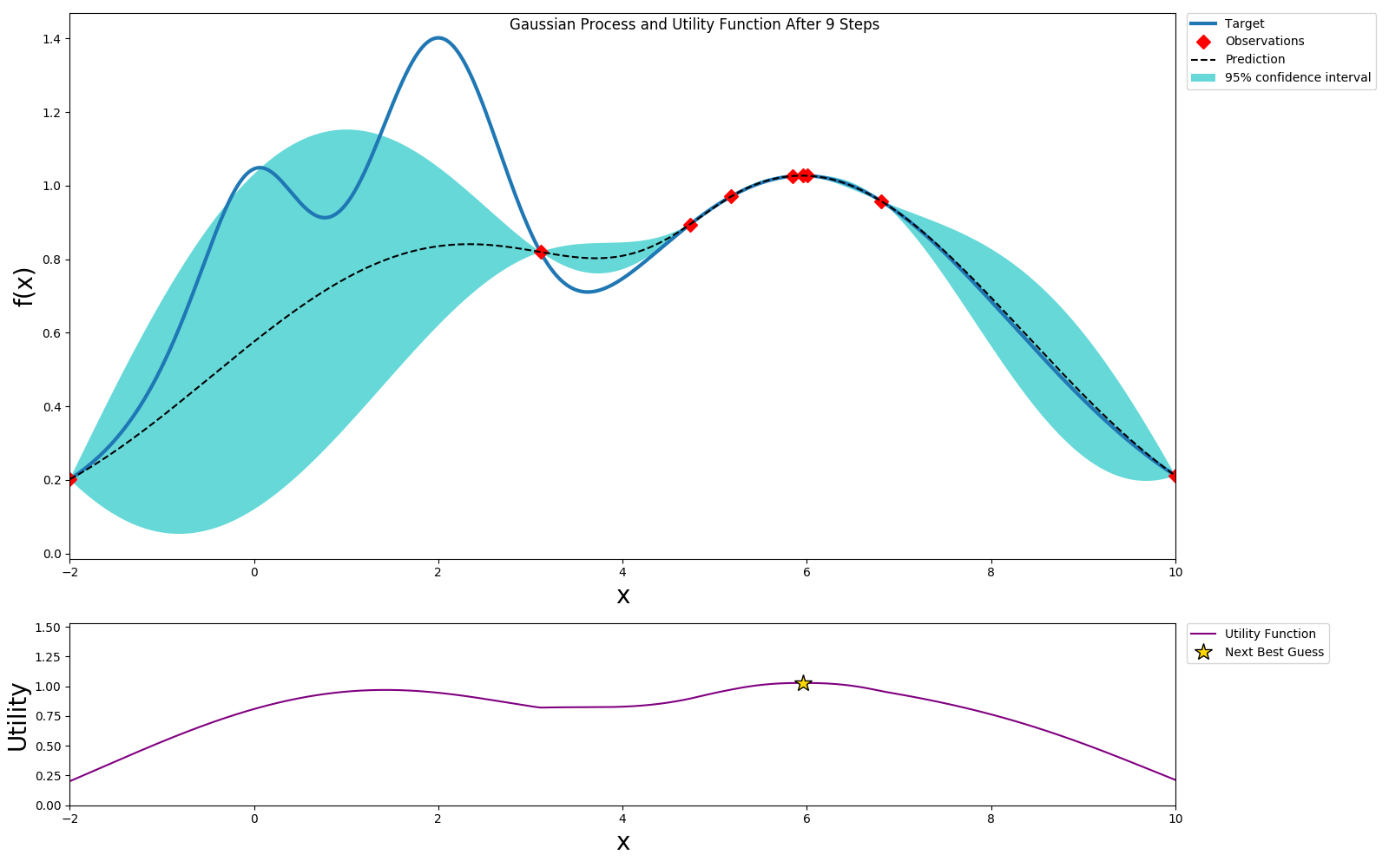
Depending on the available resources of computation and time, we can select different exploration/exploitation policies.
Now let us create a bayesian optimization experiment using Katib.
Experiment
Let us start by creating an experiment.
Random search experiment
apiVersion: "kubeflow.org/v1alpha3"
kind: Experiment
metadata:
namespace: kubeflow
name: tfjob-bayesian
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy_1
algorithm:
algorithmName: bayesianoptimization
metricsCollectorSpec:
source:
fileSystemPath:
path: /train
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: --learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
- name: --batch_size
parameterType: int
feasibleSpace:
min: "100"
max: "200"
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: "kubeflow.org/v1"
kind: TFJob
metadata:
name: {{.Trial}}
namespace: {{.NameSpace}}
spec:
tfReplicaSpecs:
Worker:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
imagePullPolicy: IfNotPresent
command:
- "python"
- "/var/tf_mnist/mnist_with_summaries.py"
- "--log_dir=/train/metrics"
{{- with .HyperParameters}}
{{- range .}}
- "{{.Name}}={{.Value}}"
{{- end}}
{{- end}}
The only difference between random search and bayesian optimization specifications is the algorithm name algorithmName: bayesianoptimization. This is the primary advantage of using Katib. We can easily try different optimizations as they are added to Katib, without having to know too much about their implementation.
Let us create the experiment.
cd $HOME/tutorial/examples/v1alpha3
kubectl apply -f tfjob-bayesian.yaml
Sample Output
experiment.kubeflow.org/tfjob-bayesian created
Check the suggestions generated by the Bayesian optimizer and see how they differ from Grid/Random searches.
kubectl -n kubeflow get suggestions tfjob-bayesian -o yaml
Sample Output
apiVersion: kubeflow.org/v1alpha3
kind: Suggestion
metadata:
creationTimestamp: "2019-10-27T19:18:49Z"
generation: 7
name: tfjob-bayesian
namespace: kubeflow
ownerReferences:
- apiVersion: kubeflow.org/v1alpha3
blockOwnerDeletion: true
controller: true
kind: Experiment
name: tfjob-bayesian
uid: 9b175325-f8ee-11e9-88ef-080027c5bc64
resourceVersion: "168437"
selfLink: /apis/kubeflow.org/v1alpha3/namespaces/kubeflow/suggestions/tfjob-bayesian
uid: 9b1d8453-f8ee-11e9-88ef-080027c5bc64
spec:
algorithmName: bayesianoptimization
requests: 9
status:
conditions:
- lastTransitionTime: "2019-10-27T19:18:49Z"
lastUpdateTime: "2019-10-27T19:18:49Z"
message: Suggestion is created
reason: SuggestionCreated
status: "True"
type: Created
- lastTransitionTime: "2019-10-27T19:19:20Z"
lastUpdateTime: "2019-10-27T19:19:20Z"
message: Deployment is ready
reason: DeploymentReady
status: "True"
type: DeploymentReady
- lastTransitionTime: "2019-10-27T19:20:20Z"
lastUpdateTime: "2019-10-27T19:20:20Z"
message: Suggestion is running
reason: SuggestionRunning
status: "True"
type: Running
startTime: "2019-10-27T19:18:49Z"
suggestionCount: 9
suggestions:
- name: tfjob-bayesian-jtj6kc7w
parameterAssignments:
- name: --learning_rate
value: "0.011057901678989632"
- name: --batch_size
value: "159"
- name: tfjob-bayesian-grk2k47g
parameterAssignments:
- name: --learning_rate
value: "0.010248006471638945"
- name: --batch_size
value: "157"
- name: tfjob-bayesian-cvhmdgmg
parameterAssignments:
- name: --learning_rate
value: "0.048420638587223536"
- name: --batch_size
value: "178"
- name: tfjob-bayesian-4m2qn7dd
parameterAssignments:
- name: --learning_rate
value: "0.0227014807837709"
- name: --batch_size
value: "172"
- name: tfjob-bayesian-gbl5kns7
parameterAssignments:
- name: --learning_rate
value: "0.02417240356426028"
- name: --batch_size
value: "165"
- name: tfjob-bayesian-zxjrcbkj
parameterAssignments:
- name: --learning_rate
value: "0.04274224243794055"
- name: --batch_size
value: "165"
- name: tfjob-bayesian-zwvf497n
parameterAssignments:
- name: --learning_rate
value: "0.047036133061507786"
- name: --batch_size
value: "133"
- name: tfjob-bayesian-xf7vthlw
parameterAssignments:
- name: --learning_rate
value: "0.018676077504433782"
- name: --batch_size
value: "145"
- name: tfjob-bayesian-jhwvd5tn
parameterAssignments:
- name: --learning_rate
value: "0.022390829243915743"
- name: --batch_size
value: "174"
Once the experiment is completed, we can check the optimal parameter values and the accuracy obtained.
kubectl -n kubeflow get experiment tfjob-bayesian -o yaml
Sample Output
apiVersion: kubeflow.org/v1alpha3
kind: Experiment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"kubeflow.org/v1alpha3","kind":"Experiment","metadata":{"annotations":{},"name":"tfjob-bayesian","namespace":"kubeflow"},"spec":{"algorithm":{"algorithmName":"bayesianoptimization"},"maxFailedTrialCount":3,"maxTrialCount":12,"metricsCollectorSpec":{"collector":{"kind":"TensorFlowEvent"},"source":{"fileSystemPath":{"kind":"Directory","path":"/train"}}},"objective":{"goal":0.99,"objectiveMetricName":"accuracy_1","type":"maximize"},"parallelTrialCount":3,"parameters":[{"feasibleSpace":{"max":"0.05","min":"0.01"},"name":"--learning_rate","parameterType":"double"},{"feasibleSpace":{"max":"200","min":"100"},"name":"--batch_size","parameterType":"int"}],"trialTemplate":{"goTemplate":{"rawTemplate":"apiVersion: \"kubeflow.org/v1\"\nkind: TFJob\nmetadata:\n name: {{.Trial}}\n namespace: {{.NameSpace}}\nspec:\n tfReplicaSpecs:\n Worker:\n replicas: 1 \n restartPolicy: OnFailure\n template:\n spec:\n containers:\n - name: tensorflow \n image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0\n imagePullPolicy: IfNotPresent\n command:\n - \"python\"\n - \"/var/tf_mnist/mnist_with_summaries.py\"\n - \"--log_dir=/train/metrics\"\n {{- with .HyperParameters}}\n {{- range .}}\n - \"{{.Name}}={{.Value}}\"\n {{- end}}\n {{- end}}"}}}}
creationTimestamp: "2019-10-27T19:18:49Z"
finalizers:
- update-prometheus-metrics
generation: 2
name: tfjob-bayesian
namespace: kubeflow
resourceVersion: "169359"
selfLink: /apis/kubeflow.org/v1alpha3/namespaces/kubeflow/experiments/tfjob-bayesian
uid: 9b175325-f8ee-11e9-88ef-080027c5bc64
spec:
algorithm:
algorithmName: bayesianoptimization
algorithmSettings: null
maxFailedTrialCount: 3
maxTrialCount: 12
metricsCollectorSpec:
collector:
kind: TensorFlowEvent
source:
fileSystemPath:
kind: Directory
path: /train
objective:
goal: 0.99
objectiveMetricName: accuracy_1
type: maximize
parallelTrialCount: 3
parameters:
- feasibleSpace:
max: "0.05"
min: "0.01"
name: --learning_rate
parameterType: double
- feasibleSpace:
max: "200"
min: "100"
name: --batch_size
parameterType: int
trialTemplate:
goTemplate:
rawTemplate: "apiVersion: \"kubeflow.org/v1\"\nkind: TFJob\nmetadata:\n name:
{{.Trial}}\n namespace: {{.NameSpace}}\nspec:\n tfReplicaSpecs:\n Worker:\n
\ replicas: 1 \n restartPolicy: OnFailure\n template:\n spec:\n
\ containers:\n - name: tensorflow \n image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0\n
\ imagePullPolicy: IfNotPresent\n command:\n -
\"python\"\n - \"/var/tf_mnist/mnist_with_summaries.py\"\n -
\"--log_dir=/train/metrics\"\n {{- with .HyperParameters}}\n
\ {{- range .}}\n - \"{{.Name}}={{.Value}}\"\n {{-
end}}\n {{- end}}"
status:
completionTime: "2019-10-27T19:29:45Z"
conditions:
- lastTransitionTime: "2019-10-27T19:18:49Z"
lastUpdateTime: "2019-10-27T19:18:49Z"
message: Experiment is created
reason: ExperimentCreated
status: "True"
type: Created
- lastTransitionTime: "2019-10-27T19:29:45Z"
lastUpdateTime: "2019-10-27T19:29:45Z"
message: Experiment is running
reason: ExperimentRunning
status: "False"
type: Running
- lastTransitionTime: "2019-10-27T19:29:45Z"
lastUpdateTime: "2019-10-27T19:29:45Z"
message: Experiment has succeeded because max trial count has reached
reason: ExperimentSucceeded
status: "True"
type: Succeeded
currentOptimalTrial:
observation:
metrics:
- name: accuracy_1
value: 0.973200023174
parameterAssignments:
- name: --learning_rate
value: "0.010248006471638945"
- name: --batch_size
value: "157"
startTime: "2019-10-27T19:18:49Z"
trials: 12
trialsSucceeded: 12
In summary, different hyperparameter tuning algorithms have different characteristics and situations where they fit better. Trying out multiple options is easy with Kubeflow/Katib.
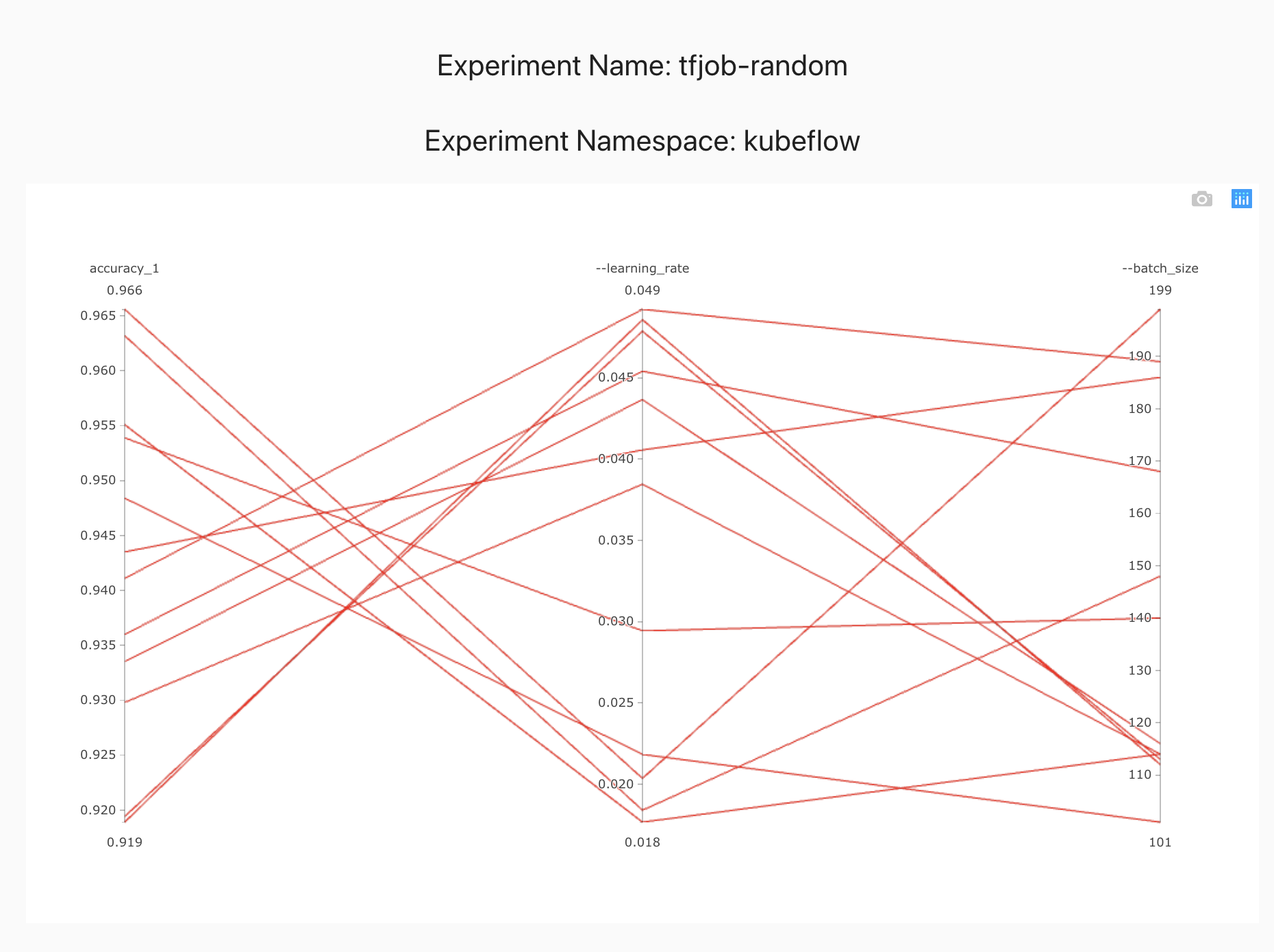
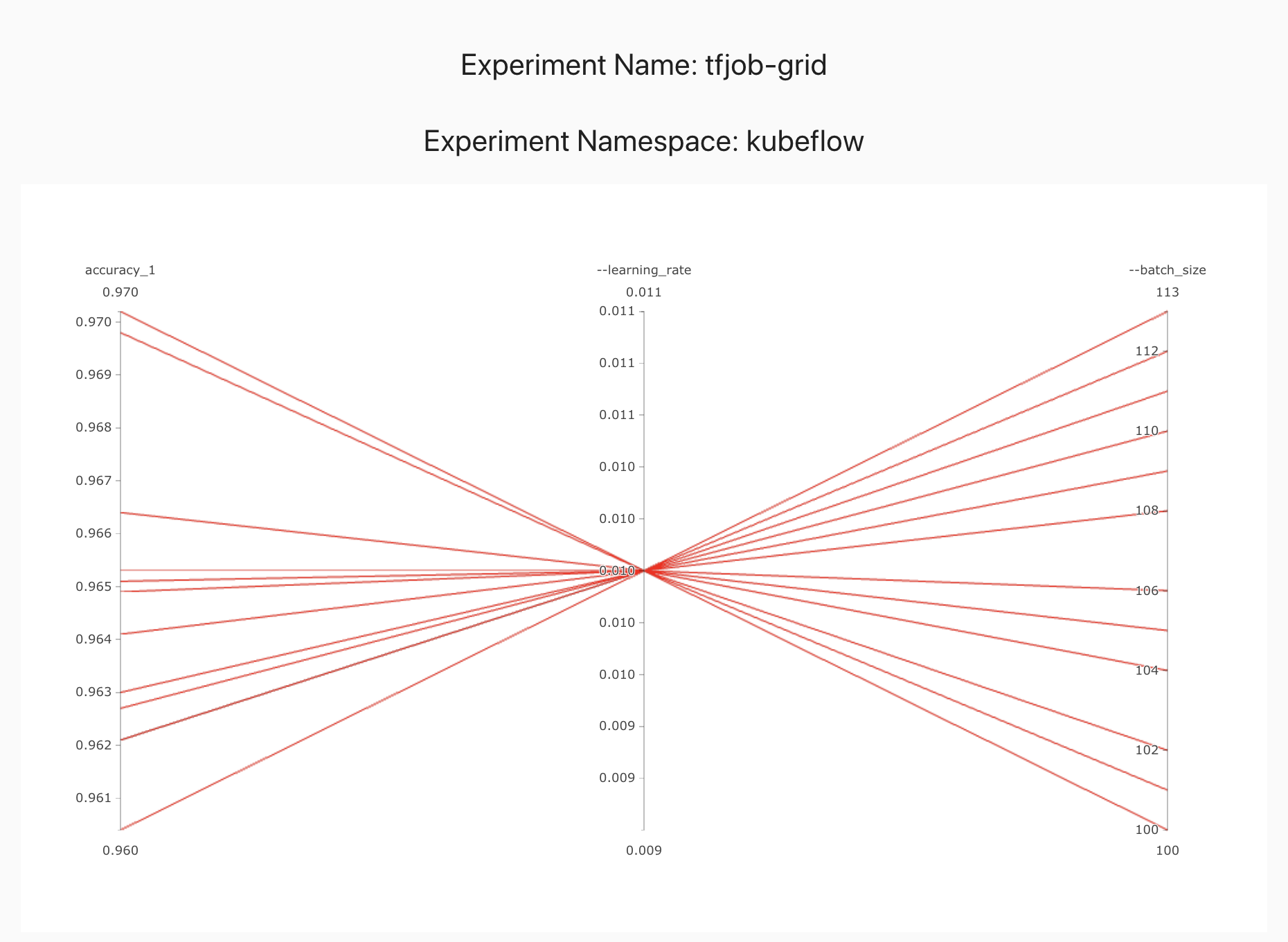
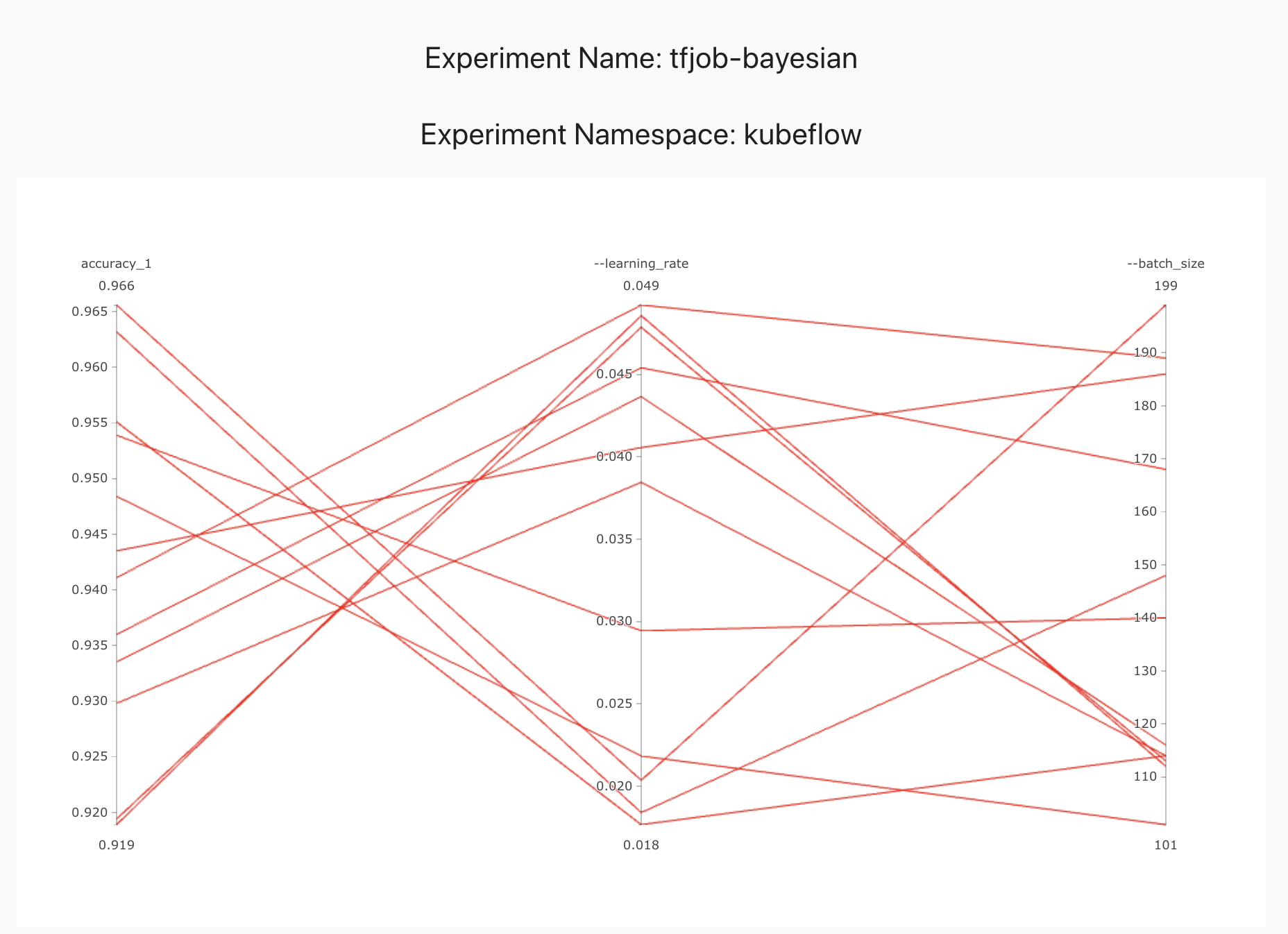
Automatic Machine Learning
Applied Machine Learning is a highly iterative process. When you are training a neural network you have to make a lot of choices - like how many layers does the network have, how many hidden units should have, what is the learning rate, what is the activation function etc. It is almost impossible to correctly guess the correct values all these hyperparameters. Intuitions from one domain do not apply well to another domain. When training a machine learning model, we want to optimize the in-sample error (Bias) and the out-of-sample error(variance). In the past we often saw that improving the bias resulted in over-fitting and high variance and vice versa. With the rise of neural networks and big data, improving bias and variance together has become feasible. We can build larger neural networks to reduce bias and train them with more data to reduce variance. How ever this exacerbates the problem of selecting optimal hyperparameters and neural network architectures. This make automatic machine learning more desirable, but also feasible as we do not have to deal with the bias/variance trade off.
Kubeflow
Install Kubeflow
Download kfctl
Instructions for Mac OS X
curl -L -O https://github.com/kubeflow/kubeflow/releases/download/v0.7.0-rc.6/kfctl_v0.7.0-rc.5-7-gc66ebff3_darwin.tar.gz
tar xf kfctl_v0.7.0-rc.5-7-gc66ebff3_darwin.tar.gz
mv kfctl-darwin /usr/local/bin/kfctl
Instructions for Linux
curl -L -O https://github.com/kubeflow/kubeflow/releases/download/v0.7.0-rc.6/kfctl_v0.7.0-rc.5-7-gc66ebff3_linux.tar.gz
tar xf kfctl_v0.7.0-rc.5-7-gc66ebff3_linux.tar.gz
sudo mv kfctl /usr/local/bin/kfctl
Create Kubeflow Configuration
export KF_DIR=kubeflow-install
mkdir $KF_DIR
cd $KF_DIR
export CONFIG_FILE=https://raw.githubusercontent.com/kubeflow/manifests/master/kfdef/kfctl_k8s_istio.yaml
kfctl apply -V -f $CONFIG_FILE
Connect to Kubeflow Central Dashboard
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
export INGRESS_HOST=$(kubectl get po -l istio=ingressgateway -n istio-system -o jsonpath={.items[0].status.hostIP})
echo http://$INGRESS_HOST:$INGRESS_PORT
Kubeflow Pipelines
Install a Python 3.x environment.
Instructions for Linux
Download pre-requisites
sudo apt-get update; sudo apt-get install -y curl bzip2
Install Miniconda
curl -L -O https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
Restart your terminal session.
Verify that conda is added to your path.
which conda
Sample Output
/home/ubuntu/miniconda3/bin/conda
Create a new Python 3 environment
conda create --name mlpipeline python=3.7
Activate the new enviroment.
conda activate mlpipeline
Install Kubeflow Pipelines SDK
pip install \
https://storage.googleapis.com/ml-pipeline/release/latest/kfp.tar.gz --upgrade
Cleanup
Deleting the vagrant VM
Go to the folder where you ran git clone in Step 1.3.
vagrant destroy
Get the list of Virtual Box VMs
vboxmanage list vms
Delete any unused VMs.
vboxmanage unregistervm <vmid from the previous step> --delete
References
https://github.com/kubeflow/katib https://github.com/kubeflow/kubeflow https://www.automl.org/book/